diff --git a/201_torch_numpy.py b/201_torch_numpy.py
deleted file mode 100644
index 4d9584b..0000000
--- a/201_torch_numpy.py
+++ /dev/null
@@ -1,63 +0,0 @@
-"""
-Know more, visit 莫烦Python: https://morvanzhou.github.io/tutorials/
-My Youtube Channel: https://www.youtube.com/user/MorvanZhou
-
-Dependencies:
-torch: 0.1.11
-numpy
-"""
-import torch
-import numpy as np
-
-# details about math operation in torch can be found in: http://pytorch.org/docs/torch.html#math-operations
-
-# convert numpy to tensor or vise versa
-np_data = np.arange(6).reshape((2, 3))
-torch_data = torch.from_numpy(np_data)
-tensor2array = torch_data.numpy()
-print(
- '\nnumpy array:', np_data, # [[0 1 2], [3 4 5]]
- '\ntorch tensor:', torch_data, # 0 1 2 \n 3 4 5 [torch.LongTensor of size 2x3]
- '\ntensor to array:', tensor2array, # [[0 1 2], [3 4 5]]
-)
-
-
-# abs
-data = [-1, -2, 1, 2]
-tensor = torch.FloatTensor(data) # 32-bit floating point
-print(
- '\nabs',
- '\nnumpy: ', np.abs(data), # [1 2 1 2]
- '\ntorch: ', torch.abs(tensor) # [1 2 1 2]
-)
-
-# sin
-print(
- '\nsin',
- '\nnumpy: ', np.sin(data), # [-0.84147098 -0.90929743 0.84147098 0.90929743]
- '\ntorch: ', torch.sin(tensor) # [-0.8415 -0.9093 0.8415 0.9093]
-)
-
-# mean
-print(
- '\nmean',
- '\nnumpy: ', np.mean(data), # 0.0
- '\ntorch: ', torch.mean(tensor) # 0.0
-)
-
-# matrix multiplication
-data = [[1,2], [3,4]]
-tensor = torch.FloatTensor(data) # 32-bit floating point
-# correct method
-print(
- '\nmatrix multiplication (matmul)',
- '\nnumpy: ', np.matmul(data, data), # [[7, 10], [15, 22]]
- '\ntorch: ', torch.mm(tensor, tensor) # [[7, 10], [15, 22]]
-)
-# incorrect method
-data = np.array(data)
-print(
- '\nmatrix multiplication (dot)',
- '\nnumpy: ', data.dot(data), # [[7, 10], [15, 22]]
- '\ntorch: ', tensor.dot(tensor) # this will convert tensor to [1,2,3,4], you'll get 30.0
-)
\ No newline at end of file
diff --git a/202_variable.py b/202_variable.py
deleted file mode 100644
index 194c2f4..0000000
--- a/202_variable.py
+++ /dev/null
@@ -1,57 +0,0 @@
-"""
-Know more, visit 莫烦Python: https://morvanzhou.github.io/tutorials/
-My Youtube Channel: https://www.youtube.com/user/MorvanZhou
-
-Dependencies:
-torch: 0.1.11
-"""
-import torch
-from torch.autograd import Variable
-
-# Variable in torch is to build a computational graph,
-# but this graph is dynamic compared with a static graph in Tensorflow or Theano.
-# So torch does not have placeholder, torch can just pass variable to the computational graph.
-
-tensor = torch.FloatTensor([[1,2],[3,4]]) # build a tensor
-variable = Variable(tensor, requires_grad=True) # build a variable, usually for compute gradients
-
-print(tensor) # [torch.FloatTensor of size 2x2]
-print(variable) # [torch.FloatTensor of size 2x2]
-
-# till now the tensor and variable seem the same.
-# However, the variable is a part of the graph, it's a part of the auto-gradient.
-
-t_out = torch.mean(tensor*tensor) # x^2
-v_out = torch.mean(variable*variable) # x^2
-print(t_out)
-print(v_out) # 7.5
-
-v_out.backward() # backpropagation from v_out
-# v_out = 1/4 * sum(variable*variable)
-# the gradients w.r.t the variable, d(v_out)/d(variable) = 1/4*2*variable = variable/2
-print(variable.grad)
-'''
- 0.5000 1.0000
- 1.5000 2.0000
-'''
-
-print(variable) # this is data in variable format
-"""
-Variable containing:
- 1 2
- 3 4
-[torch.FloatTensor of size 2x2]
-"""
-
-print(variable.data) # this is data in tensor format
-"""
- 1 2
- 3 4
-[torch.FloatTensor of size 2x2]
-"""
-
-print(variable.data.numpy()) # numpy format
-"""
-[[ 1. 2.]
- [ 3. 4.]]
-"""
\ No newline at end of file
diff --git a/203_activation.py b/203_activation.py
deleted file mode 100644
index a0c3849..0000000
--- a/203_activation.py
+++ /dev/null
@@ -1,49 +0,0 @@
-"""
-Know more, visit 莫烦Python: https://morvanzhou.github.io/tutorials/
-My Youtube Channel: https://www.youtube.com/user/MorvanZhou
-
-Dependencies:
-torch: 0.1.11
-matplotlib
-"""
-import torch
-import torch.nn.functional as F
-from torch.autograd import Variable
-import matplotlib.pyplot as plt
-
-# fake data
-x = torch.linspace(-5, 5, 200) # x data (tensor), shape=(100, 1)
-x = Variable(x)
-x_np = x.data.numpy() # numpy array for plotting
-
-# following are popular activation functions
-y_relu = F.relu(x).data.numpy()
-y_sigmoid = F.sigmoid(x).data.numpy()
-y_tanh = F.tanh(x).data.numpy()
-y_softplus = F.softplus(x).data.numpy()
-# y_softmax = F.softmax(x) softmax is a special kind of activation function, it is about probability
-
-
-# plt to visualize these activation function
-plt.figure(1, figsize=(8, 6))
-plt.subplot(221)
-plt.plot(x_np, y_relu, c='red', label='relu')
-plt.ylim((-1, 5))
-plt.legend(loc='best')
-
-plt.subplot(222)
-plt.plot(x_np, y_sigmoid, c='red', label='sigmoid')
-plt.ylim((-0.2, 1.2))
-plt.legend(loc='best')
-
-plt.subplot(223)
-plt.plot(x_np, y_tanh, c='red', label='tanh')
-plt.ylim((-1.2, 1.2))
-plt.legend(loc='best')
-
-plt.subplot(224)
-plt.plot(x_np, y_softplus, c='red', label='softplus')
-plt.ylim((-0.2, 6))
-plt.legend(loc='best')
-
-plt.show()
\ No newline at end of file
diff --git a/301_regression.py b/301_regression.py
deleted file mode 100644
index 149fac3..0000000
--- a/301_regression.py
+++ /dev/null
@@ -1,64 +0,0 @@
-"""
-Know more, visit 莫烦Python: https://morvanzhou.github.io/tutorials/
-My Youtube Channel: https://www.youtube.com/user/MorvanZhou
-
-Dependencies:
-torch: 0.1.11
-matplotlib
-"""
-import torch
-from torch.autograd import Variable
-import torch.nn.functional as F
-import matplotlib.pyplot as plt
-
-torch.manual_seed(1) # reproducible
-
-x = torch.unsqueeze(torch.linspace(-1, 1, 100), dim=1) # x data (tensor), shape=(100, 1)
-y = x.pow(2) + 0.2*torch.rand(x.size()) # noisy y data (tensor), shape=(100, 1)
-
-# torch can only train on Variable, so convert them to Variable
-x, y = Variable(x), Variable(y)
-
-# plt.scatter(x.data.numpy(), y.data.numpy())
-# plt.show()
-
-
-class Net(torch.nn.Module):
- def __init__(self, n_feature, n_hidden, n_output):
- super(Net, self).__init__()
- self.hidden = torch.nn.Linear(n_feature, n_hidden) # hidden layer
- self.predict = torch.nn.Linear(n_hidden, n_output) # output layer
-
- def forward(self, x):
- x = F.relu(self.hidden(x)) # activation function for hidden layer
- x = self.predict(x) # linear output
- return x
-
-net = Net(n_feature=1, n_hidden=10, n_output=1) # define the network
-print(net) # net architecture
-
-optimizer = torch.optim.SGD(net.parameters(), lr=0.5)
-loss_func = torch.nn.MSELoss() # this is for regression mean squared loss
-
-plt.ion() # something about plotting
-plt.show()
-
-for t in range(100):
- prediction = net(x) # input x and predict based on x
-
- loss = loss_func(prediction, y) # must be (1. nn output, 2. target)
-
- optimizer.zero_grad() # clear gradients for next train
- loss.backward() # backpropagation, compute gradients
- optimizer.step() # apply gradients
-
- if t % 5 == 0:
- # plot and show learning process
- plt.cla()
- plt.scatter(x.data.numpy(), y.data.numpy())
- plt.plot(x.data.numpy(), prediction.data.numpy(), 'r-', lw=5)
- plt.text(0.5, 0, 'Loss=%.4f' % loss.data[0], fontdict={'size': 20, 'color': 'red'})
- plt.pause(0.1)
-
-plt.ioff()
-plt.show()
\ No newline at end of file
diff --git a/302_classification.py b/302_classification.py
deleted file mode 100644
index b371395..0000000
--- a/302_classification.py
+++ /dev/null
@@ -1,72 +0,0 @@
-"""
-Know more, visit 莫烦Python: https://morvanzhou.github.io/tutorials/
-My Youtube Channel: https://www.youtube.com/user/MorvanZhou
-
-Dependencies:
-torch: 0.1.11
-matplotlib
-"""
-import torch
-from torch.autograd import Variable
-import torch.nn.functional as F
-import matplotlib.pyplot as plt
-
-torch.manual_seed(1) # reproducible
-
-# make fake data
-n_data = torch.ones(100, 2)
-x0 = torch.normal(2*n_data, 1) # class0 x data (tensor), shape=(100, 2)
-y0 = torch.zeros(100) # class0 y data (tensor), shape=(100, 1)
-x1 = torch.normal(-2*n_data, 1) # class1 x data (tensor), shape=(100, 2)
-y1 = torch.ones(100) # class1 y data (tensor), shape=(100, 1)
-x = torch.cat((x0, x1), 0).type(torch.FloatTensor) # FloatTensor = 32-bit floating
-y = torch.cat((y0, y1), ).type(torch.LongTensor) # LongTensor = 64-bit integer
-
-# torch can only train on Variable, so convert them to Variable
-x, y = Variable(x), Variable(y)
-
-# plt.scatter(x.data.numpy()[:, 0], x.data.numpy()[:, 1], c=y.data.numpy(), s=100, lw=0, cmap='RdYlGn')
-# plt.show()
-
-
-class Net(torch.nn.Module):
- def __init__(self, n_feature, n_hidden, n_output):
- super(Net, self).__init__()
- self.hidden = torch.nn.Linear(n_feature, n_hidden) # hidden layer
- self.out = torch.nn.Linear(n_hidden, n_output) # output layer
-
- def forward(self, x):
- x = F.relu(self.hidden(x)) # activation function for hidden layer
- x = self.out(x)
- return x
-
-net = Net(n_feature=2, n_hidden=10, n_output=2) # define the network
-print(net) # net architecture
-
-optimizer = torch.optim.SGD(net.parameters(), lr=0.02)
-loss_func = torch.nn.CrossEntropyLoss() # the target label is not one-hotted
-
-plt.ion() # something about plotting
-plt.show()
-
-for t in range(100):
- out = net(x) # input x and predict based on x
- loss = loss_func(out, y) # must be (1. nn output, 2. target), the target label is not one-hotted
-
- optimizer.zero_grad() # clear gradients for next train
- loss.backward() # backpropagation, compute gradients
- optimizer.step() # apply gradients
-
- if t % 2 == 0:
- # plot and show learning process
- plt.cla()
- prediction = torch.max(F.softmax(out), 1)[1]
- pred_y = prediction.data.numpy().squeeze()
- target_y = y.data.numpy()
- plt.scatter(x.data.numpy()[:, 0], x.data.numpy()[:, 1], c=pred_y, s=100, lw=0, cmap='RdYlGn')
- accuracy = sum(pred_y == target_y)/200
- plt.text(1.5, -4, 'Accuracy=%.2f' % accuracy, fontdict={'size': 20, 'color': 'red'})
- plt.pause(0.1)
-
-plt.ioff()
-plt.show()
\ No newline at end of file
diff --git a/303_build_nn_quickly.py b/303_build_nn_quickly.py
deleted file mode 100644
index de19845..0000000
--- a/303_build_nn_quickly.py
+++ /dev/null
@@ -1,35 +0,0 @@
-"""
-Know more, visit 莫烦Python: https://morvanzhou.github.io/tutorials/
-My Youtube Channel: https://www.youtube.com/user/MorvanZhou
-
-Dependencies:
-torch: 0.1.11
-"""
-import torch
-import torch.nn.functional as F
-
-
-# replace following class code with an easy sequential network
-class Net(torch.nn.Module):
- def __init__(self, n_feature, n_hidden, n_output):
- super(Net, self).__init__()
- self.hidden = torch.nn.Linear(n_feature, n_hidden) # hidden layer
- self.predict = torch.nn.Linear(n_hidden, n_output) # output layer
-
- def forward(self, x):
- x = F.relu(self.hidden(x)) # activation function for hidden layer
- x = self.predict(x) # linear output
- return x
-
-net1 = Net(1, 10, 1)
-
-# easy and fast way to build your network
-net2 = torch.nn.Sequential(
- torch.nn.Linear(1, 10),
- torch.nn.ReLU(),
- torch.nn.Linear(10, 1)
-)
-
-
-print(net1) # net1 architecture
-print(net2) # net2 architecture
\ No newline at end of file
diff --git a/304_save_reload.py b/304_save_reload.py
deleted file mode 100644
index 8c28824..0000000
--- a/304_save_reload.py
+++ /dev/null
@@ -1,88 +0,0 @@
-"""
-Know more, visit 莫烦Python: https://morvanzhou.github.io/tutorials/
-My Youtube Channel: https://www.youtube.com/user/MorvanZhou
-
-Dependencies:
-torch: 0.1.11
-matplotlib
-"""
-import torch
-from torch.autograd import Variable
-import matplotlib.pyplot as plt
-
-torch.manual_seed(1) # reproducible
-
-# fake data
-x = torch.unsqueeze(torch.linspace(-1, 1, 100), dim=1) # x data (tensor), shape=(100, 1)
-y = x.pow(2) + 0.2*torch.rand(x.size()) # noisy y data (tensor), shape=(100, 1)
-x, y = Variable(x, requires_grad=False), Variable(y, requires_grad=False)
-
-
-def save():
- # save net1
- net1 = torch.nn.Sequential(
- torch.nn.Linear(1, 10),
- torch.nn.ReLU(),
- torch.nn.Linear(10, 1)
- )
- optimizer = torch.optim.SGD(net1.parameters(), lr=0.5)
- loss_func = torch.nn.MSELoss()
-
- for t in range(100):
- prediction = net1(x)
- loss = loss_func(prediction, y)
- optimizer.zero_grad()
- loss.backward()
- optimizer.step()
-
- # plot result
- plt.figure(1, figsize=(10, 3))
- plt.subplot(131)
- plt.title('Net1')
- plt.scatter(x.data.numpy(), y.data.numpy())
- plt.plot(x.data.numpy(), prediction.data.numpy(), 'r-', lw=5)
-
- # 2 ways to save the net
- torch.save(net1, 'net.pkl') # save entire net
- torch.save(net1.state_dict(), 'net_params.pkl') # save only the parameters
-
-
-def restore_net():
- # restore entire net1 to net2
- net2 = torch.load('net.pkl')
- prediction = net2(x)
-
- # plot result
- plt.subplot(132)
- plt.title('Net2')
- plt.scatter(x.data.numpy(), y.data.numpy())
- plt.plot(x.data.numpy(), prediction.data.numpy(), 'r-', lw=5)
-
-
-def restore_params():
- # restore only the parameters in net1 to net3
- net3 = torch.nn.Sequential(
- torch.nn.Linear(1, 10),
- torch.nn.ReLU(),
- torch.nn.Linear(10, 1)
- )
-
- # copy net1's parameters into net3
- net3.load_state_dict(torch.load('net_params.pkl'))
- prediction = net3(x)
-
- # plot result
- plt.subplot(133)
- plt.title('Net3')
- plt.scatter(x.data.numpy(), y.data.numpy())
- plt.plot(x.data.numpy(), prediction.data.numpy(), 'r-', lw=5)
- plt.show()
-
-# save net1
-save()
-
-# restore entire net (may slow)
-restore_net()
-
-# restore only the net parameters
-restore_params()
diff --git a/305_batch_train.py b/305_batch_train.py
deleted file mode 100644
index 4a09232..0000000
--- a/305_batch_train.py
+++ /dev/null
@@ -1,31 +0,0 @@
-"""
-Know more, visit 莫烦Python: https://morvanzhou.github.io/tutorials/
-My Youtube Channel: https://www.youtube.com/user/MorvanZhou
-
-Dependencies:
-torch: 0.1.11
-"""
-import torch
-import torch.utils.data as Data
-
-torch.manual_seed(1) # reproducible
-
-BATCH_SIZE = 5
-# BATCH_SIZE = 8
-
-x = torch.linspace(1, 10, 10) # this is x data (torch tensor)
-y = torch.linspace(10, 1, 10) # this is y data (torch tensor)
-
-torch_dataset = Data.TensorDataset(data_tensor=x, target_tensor=y)
-loader = Data.DataLoader(
- dataset=torch_dataset, # torch TensorDataset format
- batch_size=BATCH_SIZE, # mini batch size
- shuffle=True, # random shuffle for training
- num_workers=2, # subprocesses for loading data
-)
-
-for epoch in range(3): # train entire dataset 3 times
- for step, (batch_x, batch_y) in enumerate(loader): # for each training step
- # train your data...
- print('Epoch: ', epoch, '| Step: ', step, '| batch x: ',
- batch_x.numpy(), '| batch y: ', batch_y.numpy())
diff --git a/306_optimizer.py b/306_optimizer.py
deleted file mode 100644
index ab2809d..0000000
--- a/306_optimizer.py
+++ /dev/null
@@ -1,85 +0,0 @@
-"""
-Know more, visit 莫烦Python: https://morvanzhou.github.io/tutorials/
-My Youtube Channel: https://www.youtube.com/user/MorvanZhou
-
-Dependencies:
-torch: 0.1.11
-matplotlib
-"""
-import torch
-import torch.utils.data as Data
-import torch.nn.functional as F
-from torch.autograd import Variable
-import matplotlib.pyplot as plt
-
-torch.manual_seed(1) # reproducible
-
-LR = 0.01
-BATCH_SIZE = 32
-EPOCH = 12
-
-# fake dataset
-x = torch.unsqueeze(torch.linspace(-1, 1, 1000), dim=1)
-y = x.pow(2) + 0.1*torch.normal(torch.zeros(*x.size()))
-
-# plot dataset
-plt.scatter(x.numpy(), y.numpy())
-plt.show()
-
-# put dateset into torch dataset
-torch_dataset = Data.TensorDataset(data_tensor=x, target_tensor=y)
-loader = Data.DataLoader(dataset=torch_dataset, batch_size=BATCH_SIZE, shuffle=True, num_workers=2,)
-
-
-# default network
-class Net(torch.nn.Module):
- def __init__(self):
- super(Net, self).__init__()
- self.hidden = torch.nn.Linear(1, 20) # hidden layer
- self.predict = torch.nn.Linear(20, 1) # output layer
-
- def forward(self, x):
- x = F.relu(self.hidden(x)) # activation function for hidden layer
- x = self.predict(x) # linear output
- return x
-
-# different nets
-net_SGD = Net()
-net_Momentum = Net()
-net_RMSprop = Net()
-net_Adam = Net()
-nets = [net_SGD, net_Momentum, net_RMSprop, net_Adam]
-
-# different optimizers
-opt_SGD = torch.optim.SGD(net_SGD.parameters(), lr=LR)
-opt_Momentum = torch.optim.SGD(net_Momentum.parameters(), lr=LR, momentum=0.8)
-opt_RMSprop = torch.optim.RMSprop(net_RMSprop.parameters(), lr=LR, alpha=0.9)
-opt_Adam = torch.optim.Adam(net_Adam.parameters(), lr=LR, betas=(0.9, 0.99))
-optimizers = [opt_SGD, opt_Momentum, opt_RMSprop, opt_Adam]
-
-loss_func = torch.nn.MSELoss()
-losses_his = [[], [], [], []] # record loss
-
-# training
-for epoch in range(EPOCH):
- print('Epoch: ', epoch)
- for step, (batch_x, batch_y) in enumerate(loader): # for each training step
- b_x = Variable(batch_x)
- b_y = Variable(batch_y)
-
- for net, opt, l_his in zip(nets, optimizers, losses_his):
- output = net(b_x) # get output for every net
- loss = loss_func(output, b_y) # compute loss for every net
- opt.zero_grad() # clear gradients for next train
- loss.backward() # backpropagation, compute gradients
- opt.step() # apply gradients
- l_his.append(loss.data[0]) # loss recoder
-
-labels = ['SGD', 'Momentum', 'RMSprop', 'Adam']
-for i, l_his in enumerate(losses_his):
- plt.plot(l_his, label=labels[i])
-plt.legend(loc='best')
-plt.xlabel('Steps')
-plt.ylabel('Loss')
-plt.ylim((0, 0.2))
-plt.show()
diff --git a/401_CNN.py b/401_CNN.py
deleted file mode 100644
index f6904ee..0000000
--- a/401_CNN.py
+++ /dev/null
@@ -1,109 +0,0 @@
-"""
-Know more, visit 莫烦Python: https://morvanzhou.github.io/tutorials/
-My Youtube Channel: https://www.youtube.com/user/MorvanZhou
-
-Dependencies:
-torch: 0.1.11
-torchvision
-matplotlib
-"""
-import torch
-import torch.nn as nn
-from torch.autograd import Variable
-import torch.utils.data as Data
-import torchvision
-import matplotlib.pyplot as plt
-
-torch.manual_seed(1) # reproducible
-
-# Hyper Parameters
-EPOCH = 1 # train the training data n times, to save time, we just train 1 epoch
-BATCH_SIZE = 50
-LR = 0.001 # learning rate
-DOWNLOAD_MNIST = False
-
-
-# Mnist digits dataset
-train_data = torchvision.datasets.MNIST(
- root='./mnist/',
- train=True, # this is training data
- transform=torchvision.transforms.ToTensor(), # Converts a PIL.Image or numpy.ndarray to
- # torch.FloatTensor of shape (C x H x W) and normalize in the range [0.0, 1.0]
- download=DOWNLOAD_MNIST, # download it if you don't have it
-)
-
-# plot one example
-print(train_data.train_data.size()) # (60000, 28, 28)
-print(train_data.train_labels.size()) # (60000)
-plt.imshow(train_data.train_data[0].numpy(), cmap='gray')
-plt.title('%i' % train_data.train_labels[0])
-plt.show()
-
-# Data Loader for easy mini-batch return in training, the image batch shape will be (50, 1, 28, 28)
-train_loader = Data.DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)
-
-# convert test data into Variable, pick 2000 samples to speed up testing
-test_data = torchvision.datasets.MNIST(root='./mnist/', train=False)
-test_x = Variable(torch.unsqueeze(test_data.test_data, dim=1), volatile=True).type(torch.FloatTensor)[:2000]/255. # shape from (2000, 28, 28) to (2000, 1, 28, 28), value in range(0,1)
-test_y = test_data.test_labels[:2000]
-
-
-class CNN(nn.Module):
- def __init__(self):
- super(CNN, self).__init__()
- self.conv1 = nn.Sequential( # input shape (1, 28, 28)
- nn.Conv2d(
- in_channels=1, # input height
- out_channels=16, # n_filters
- kernel_size=5, # filter size
- stride=1, # filter movement/step
- padding=2, # if want same width and length of this image after con2d, padding=(kernel_size-1)/2 if stride=1
- ), # output shape (16, 28, 28)
- nn.ReLU(), # activation
- nn.MaxPool2d(kernel_size=2), # choose max value in 2x2 area, output shape (16, 14, 14)
- )
- self.conv2 = nn.Sequential( # input shape (1, 28, 28)
- nn.Conv2d(16, 32, 5, 1, 2), # output shape (32, 14, 14)
- nn.ReLU(), # activation
- nn.MaxPool2d(2), # output shape (32, 7, 7)
- )
- self.out = nn.Linear(32 * 7 * 7, 10) # fully connected layer, output 10 classes
-
- def forward(self, x):
- x = self.conv1(x)
- x = self.conv2(x)
- x = x.view(x.size(0), -1) # flatten the output of conv2 to (batch_size, 32 * 7 * 7)
- output = self.out(x)
- return output
-
-
-cnn = CNN()
-print(cnn) # net architecture
-
-optimizer = torch.optim.Adam(cnn.parameters(), lr=LR) # optimize all cnn parameters
-loss_func = nn.CrossEntropyLoss() # the target label is not one-hotted
-
-# training and testing
-for epoch in range(EPOCH):
- for step, (x, y) in enumerate(train_loader): # gives batch data, normalize x when iterate train_loader
- b_x = Variable(x) # batch x
- b_y = Variable(y) # batch y
-
- output = cnn(b_x) # cnn output
- loss = loss_func(output, b_y) # cross entropy loss
- optimizer.zero_grad() # clear gradients for this training step
- loss.backward() # backpropagation, compute gradients
- optimizer.step() # apply gradients
-
- if step % 50 == 0:
- test_output = cnn(test_x)
- pred_y = torch.max(test_output, 1)[1].data.squeeze()
- accuracy = sum(pred_y == test_y) / test_y.size(0)
- print('Epoch: ', epoch, '| train loss: %.4f' % loss.data[0], '| test accuracy: %.2f' % accuracy)
-
-
-# print 10 predictions from test data
-test_output = cnn(test_x[:10])
-pred_y = torch.max(test_output, 1)[1].data.numpy().squeeze()
-print(pred_y, 'prediction number')
-print(test_y[:10].numpy(), 'real number')
diff --git a/402_RNN_classifier.py b/402_RNN_classifier.py
deleted file mode 100644
index 6e08739..0000000
--- a/402_RNN_classifier.py
+++ /dev/null
@@ -1,108 +0,0 @@
-"""
-Know more, visit 莫烦Python: https://morvanzhou.github.io/tutorials/
-My Youtube Channel: https://www.youtube.com/user/MorvanZhou
-
-Dependencies:
-torch: 0.1.11
-matplotlib
-torchvision
-"""
-import torch
-from torch import nn
-from torch.autograd import Variable
-import torchvision.datasets as dsets
-import torchvision.transforms as transforms
-import matplotlib.pyplot as plt
-
-
-torch.manual_seed(1) # reproducible
-
-# Hyper Parameters
-EPOCH = 1 # train the training data n times, to save time, we just train 1 epoch
-BATCH_SIZE = 64
-TIME_STEP = 28 # rnn time step / image height
-INPUT_SIZE = 28 # rnn input size / image width
-LR = 0.01 # learning rate
-DOWNLOAD_MNIST = False # set to True if haven't download the data
-
-
-# Mnist digital dataset
-train_data = dsets.MNIST(
- root='./mnist/',
- train=True, # this is training data
- transform=transforms.ToTensor(), # Converts a PIL.Image or numpy.ndarray to
- # torch.FloatTensor of shape (C x H x W) and normalize in the range [0.0, 1.0]
- download=DOWNLOAD_MNIST, # download it if you don't have it
-)
-
-# plot one example
-print(train_data.train_data.size()) # (60000, 28, 28)
-print(train_data.train_labels.size()) # (60000)
-plt.imshow(train_data.train_data[0].numpy(), cmap='gray')
-plt.title('%i' % train_data.train_labels[0])
-plt.show()
-
-# Data Loader for easy mini-batch return in training
-train_loader = torch.utils.data.DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)
-
-# convert test data into Variable, pick 2000 samples to speed up testing
-test_data = dsets.MNIST(root='./mnist/', train=False, transform=transforms.ToTensor())
-test_x = Variable(test_data.test_data, volatile=True).type(torch.FloatTensor)[:2000]/255. # shape (2000, 28, 28) value in range(0,1)
-test_y = test_data.test_labels.numpy().squeeze()[:2000] # covert to numpy array
-
-
-class RNN(nn.Module):
- def __init__(self):
- super(RNN, self).__init__()
-
- self.rnn = nn.LSTM( # if use nn.RNN(), it hardly learns
- input_size=28,
- hidden_size=64, # rnn hidden unit
- num_layers=1, # number of rnn layer
- batch_first=True, # input & output will has batch size as 1s dimension. e.g. (batch, time_step, input_size)
- )
-
- self.out = nn.Linear(64, 10)
-
- def forward(self, x):
- # x shape (batch, time_step, input_size)
- # r_out shape (batch, time_step, output_size)
- # h_n shape (n_layers, batch, hidden_size)
- # h_c shape (n_layers, batch, hidden_size)
- r_out, (h_n, h_c) = self.rnn(x, None) # None represents zero initial hidden state
-
- # choose r_out at the last time step
- out = self.out(r_out[:, -1, :])
- return out
-
-
-rnn = RNN()
-print(rnn)
-
-optimizer = torch.optim.Adam(rnn.parameters(), lr=LR) # optimize all cnn parameters
-loss_func = nn.CrossEntropyLoss() # the target label is not one-hotted
-
-# training and testing
-for epoch in range(EPOCH):
- for step, (x, y) in enumerate(train_loader): # gives batch data
- b_x = Variable(x.view(-1, 28, 28)) # reshape x to (batch, time_step, input_size)
- b_y = Variable(y) # batch y
-
- output = rnn(b_x) # rnn output
- loss = loss_func(output, b_y) # cross entropy loss
- optimizer.zero_grad() # clear gradients for this training step
- loss.backward() # backpropagation, compute gradients
- optimizer.step() # apply gradients
-
- if step % 50 == 0:
- test_output = rnn(test_x) # (samples, time_step, input_size)
- pred_y = torch.max(test_output, 1)[1].data.numpy().squeeze()
- accuracy = sum(pred_y == test_y) / test_y.size
- print('Epoch: ', epoch, '| train loss: %.4f' % loss.data[0], '| test accuracy: %.2f' % accuracy)
-
-# print 10 predictions from test data
-test_output = rnn(test_x[:10].view(-1, 28, 28))
-pred_y = torch.max(test_output, 1)[1].data.numpy().squeeze()
-print(pred_y, 'prediction number')
-print(test_y[:10], 'real number')
-
diff --git a/403_RNN_regressor.py b/403_RNN_regressor.py
deleted file mode 100644
index 7624676..0000000
--- a/403_RNN_regressor.py
+++ /dev/null
@@ -1,96 +0,0 @@
-"""
-Know more, visit 莫烦Python: https://morvanzhou.github.io/tutorials/
-My Youtube Channel: https://www.youtube.com/user/MorvanZhou
-
-Dependencies:
-torch: 0.1.11
-matplotlib
-numpy
-"""
-import torch
-from torch import nn
-from torch.autograd import Variable
-import numpy as np
-import matplotlib.pyplot as plt
-
-torch.manual_seed(1) # reproducible
-
-# Hyper Parameters
-BATCH_SIZE = 64
-TIME_STEP = 5 # rnn time step
-INPUT_SIZE = 1 # rnn input size
-LR = 0.02 # learning rate
-
-# show data
-steps = np.linspace(0, np.pi*2, 100, dtype=np.float32)
-x_np = np.sin(steps) # float32 for converting torch FloatTensor
-y_np = np.cos(steps)
-plt.plot(steps, y_np, 'r-', label='target (cos)')
-plt.plot(steps, x_np, 'b-', label='input (sin)')
-plt.legend(loc='best')
-plt.show()
-
-
-class RNN(nn.Module):
- def __init__(self):
- super(RNN, self).__init__()
-
- self.rnn = nn.RNN(
- input_size=1,
- hidden_size=32, # rnn hidden unit
- num_layers=1, # number of rnn layer
- batch_first=True, # input & output will has batch size as 1s dimension. e.g. (batch, time_step, input_size)
- )
- self.out = nn.Linear(32, 1)
-
- def forward(self, x, h_state):
- # x (batch, time_step, input_size)
- # h_state (n_layers, batch, hidden_size)
- # r_out (batch, time_step, output_size)
- r_out, h_state = self.rnn(x, h_state)
-
- outs = [] # save all predictions
- for time_step in range(r_out.size(1)): # calculate output for each time step
- outs.append(self.out(r_out[:, time_step, :]))
- return torch.stack(outs, dim=1), h_state
-
-
-rnn = RNN()
-print(rnn)
-
-optimizer = torch.optim.Adam(rnn.parameters(), lr=LR) # optimize all cnn parameters
-loss_func = nn.MSELoss()
-
-h_state = None # for initial hidden state
-
-plt.figure(1, figsize=(12, 5))
-plt.ion() # continuously plot
-plt.show()
-
-for step in range(60):
- start, end = step * np.pi, (step+1)*np.pi # time steps
- # use sin predicts cos
- steps = np.linspace(start, end, 10, dtype=np.float32)
- x_np = np.sin(steps) # float32 for converting torch FloatTensor
- y_np = np.cos(steps)
-
- x = Variable(torch.from_numpy(x_np[np.newaxis, :, np.newaxis])) # shape (batch, time_step, input_size)
- y = Variable(torch.from_numpy(y_np[np.newaxis, :, np.newaxis]))
-
- prediction, h_state = rnn(x, h_state) # rnn output
- # !! next step is important !!
- h_state = Variable(h_state.data) # repack the hidden state, break the connection from last iteration
-
- loss = loss_func(prediction, y) # cross entropy loss
- optimizer.zero_grad() # clear gradients for this training step
- loss.backward() # backpropagation, compute gradients
- optimizer.step() # apply gradients
-
- # plotting
- plt.plot(steps, y_np.flatten(), 'r-')
- plt.plot(steps, prediction.data.numpy().flatten(), 'b-')
- plt.draw()
- plt.pause(0.05)
-
-plt.ioff()
-plt.show()
diff --git a/404_autoencoder.py b/404_autoencoder.py
deleted file mode 100644
index 17d1476..0000000
--- a/404_autoencoder.py
+++ /dev/null
@@ -1,142 +0,0 @@
-"""
-Know more, visit 莫烦Python: https://morvanzhou.github.io/tutorials/
-My Youtube Channel: https://www.youtube.com/user/MorvanZhou
-
-Dependencies:
-torch: 0.1.11
-matplotlib
-numpy
-"""
-import torch
-import torch.nn as nn
-from torch.autograd import Variable
-import torch.utils.data as Data
-import torchvision
-import matplotlib.pyplot as plt
-from mpl_toolkits.mplot3d import Axes3D
-from matplotlib import cm
-import numpy as np
-
-
-torch.manual_seed(1) # reproducible
-
-# Hyper Parameters
-EPOCH = 10
-BATCH_SIZE = 64
-LR = 0.005 # learning rate
-DOWNLOAD_MNIST = False
-N_TEST_IMG = 5
-
-# Mnist digits dataset
-train_data = torchvision.datasets.MNIST(
- root='./mnist/',
- train=True, # this is training data
- transform=torchvision.transforms.ToTensor(), # Converts a PIL.Image or numpy.ndarray to
- # torch.FloatTensor of shape (C x H x W) and normalize in the range [0.0, 1.0]
- download=DOWNLOAD_MNIST, # download it if you don't have it
-)
-
-# plot one example
-print(train_data.train_data.size()) # (60000, 28, 28)
-print(train_data.train_labels.size()) # (60000)
-# plt.imshow(train_data.train_data[2].numpy(), cmap='gray')
-# plt.title('%i' % train_data.train_labels[2])
-# plt.show()
-
-# Data Loader for easy mini-batch return in training, the image batch shape will be (50, 1, 28, 28)
-train_loader = Data.DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)
-
-
-class AutoEncoder(nn.Module):
- def __init__(self):
- super(AutoEncoder, self).__init__()
-
- self.encoder = nn.Sequential(
- nn.Linear(28*28, 128),
- nn.Tanh(),
- nn.Linear(128, 64),
- nn.Tanh(),
- nn.Linear(64, 12),
- nn.Tanh(),
- nn.Linear(12, 3), # compress to 3 features which can be visualized in plt
- )
- self.decoder = nn.Sequential(
- nn.Linear(3, 12),
- nn.Tanh(),
- nn.Linear(12, 64),
- nn.Tanh(),
- nn.Linear(64, 128),
- nn.Tanh(),
- nn.Linear(128, 28*28),
- nn.Sigmoid(), # compress to a range (0, 1)
- )
-
- def forward(self, x):
- encoded = self.encoder(x)
- decoded = self.decoder(encoded)
- return encoded, decoded
-
-
-autoencoder = AutoEncoder()
-
-optimizer = torch.optim.Adam(autoencoder.parameters(), lr=LR)
-loss_func = nn.MSELoss()
-
-# initialize figure
-f, a = plt.subplots(2, N_TEST_IMG, figsize=(5, 2))
-plt.ion() # continuously plot
-plt.show()
-
-# original data (first row) for viewing
-view_data = Variable(train_data.train_data[:N_TEST_IMG].view(-1, 28*28).type(torch.FloatTensor)/255.)
-for i in range(N_TEST_IMG):
- a[0][i].imshow(np.reshape(view_data.data.numpy()[i], (28, 28)), cmap='gray')
- a[0][i].set_xticks(())
- a[0][i].set_yticks(())
-
-for epoch in range(EPOCH):
- for step, (x, y) in enumerate(train_loader):
- b_x = Variable(x.view(-1, 28*28)) # batch x, shape (batch, 28*28)
- b_y = Variable(x.view(-1, 28*28)) # batch y, shape (batch, 28*28)
- b_label = Variable(y) # batch label
-
- encoded, decoded = autoencoder(b_x)
-
- loss = loss_func(decoded, b_y) # mean square error
- optimizer.zero_grad() # clear gradients for this training step
- loss.backward() # backpropagation, compute gradients
- optimizer.step() # apply gradients
-
- if step % 100 == 0:
- print('Epoch: ', epoch, '| train loss: %.4f' % loss.data[0])
-
- # plotting decoded image (second row)
- _, decoded_data = autoencoder(view_data)
- for i in range(N_TEST_IMG):
- a[1][i].clear()
- a[1][i].imshow(np.reshape(decoded_data.data.numpy()[i], (28, 28)), cmap='gray')
- a[1][i].set_xticks(())
- a[1][i].set_yticks(())
- plt.draw()
- plt.pause(0.05)
-
-plt.ioff()
-plt.show()
-
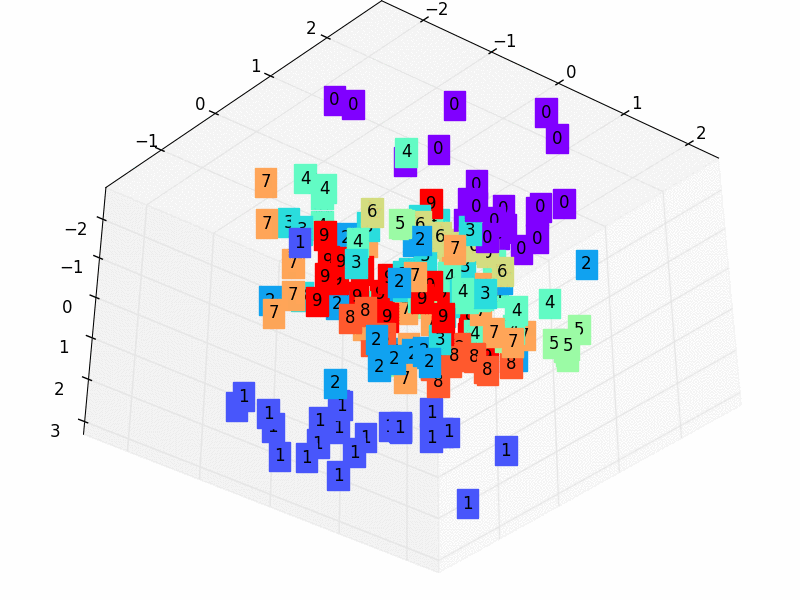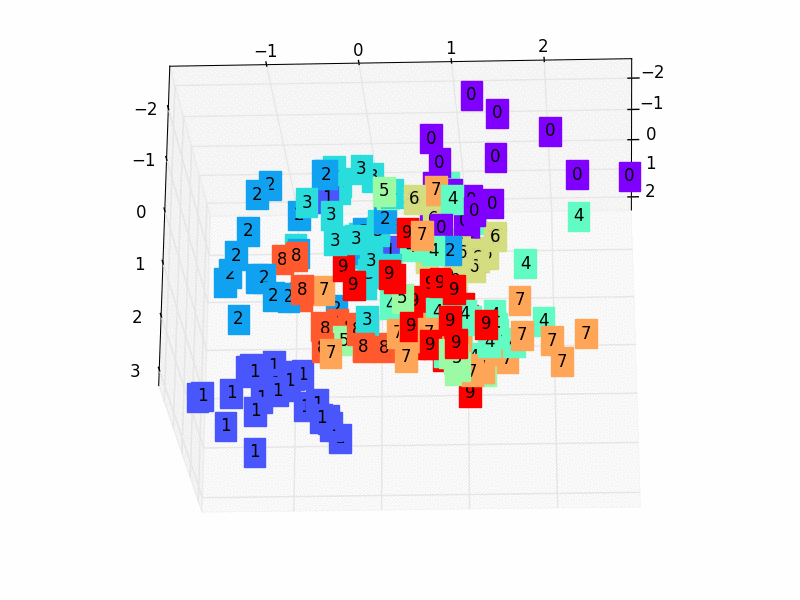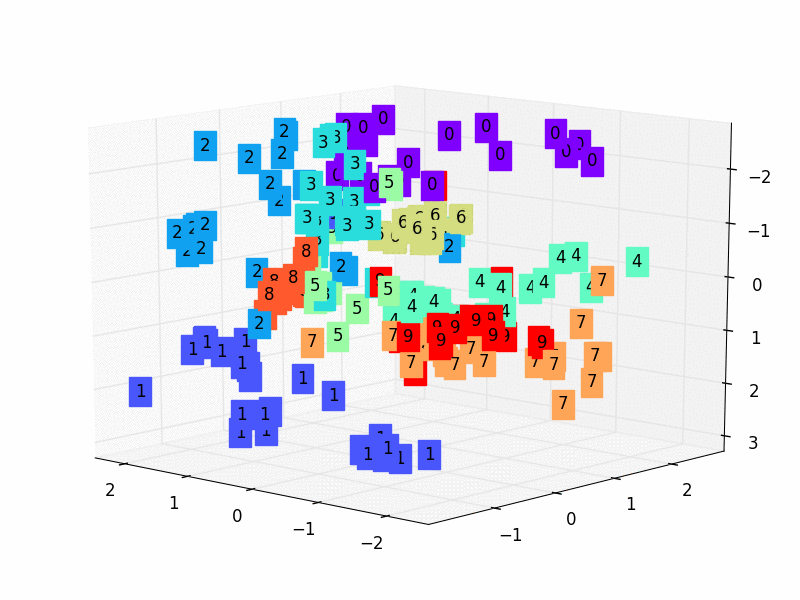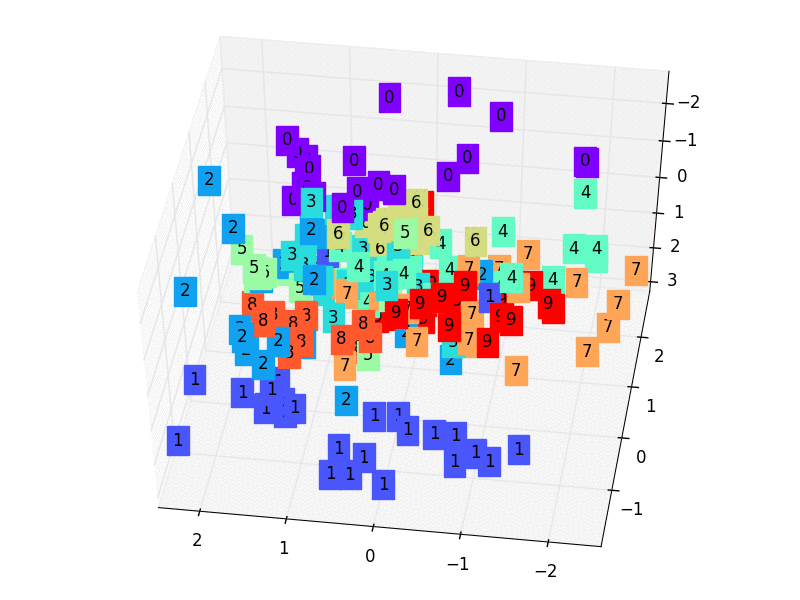
-# visualize in 3D plot
-view_data = Variable(train_data.train_data[:200].view(-1, 28*28).type(torch.FloatTensor)/255.)
-encoded_data, _ = autoencoder(view_data)
-fig = plt.figure(2)
-ax = Axes3D(fig)
-X = encoded_data.data[:, 0].numpy()
-Y = encoded_data.data[:, 1].numpy()
-Z = encoded_data.data[:, 2].numpy()
-values = train_data.train_labels[:200].numpy()
-for x, y, z, s in zip(X, Y, Z, values):
- c = cm.rainbow(int(255*s/9))
- ax.text(x, y, z, s, backgroundcolor=c)
-ax.set_xlim(X.min(), X.max())
-ax.set_ylim(Y.min(), Y.max())
-ax.set_zlim(Z.min(), Z.max())
-plt.show()
-
diff --git a/405_DQN_Reinforcement_learning.py b/405_DQN_Reinforcement_learning.py
deleted file mode 100644
index 0b0370b..0000000
--- a/405_DQN_Reinforcement_learning.py
+++ /dev/null
@@ -1,129 +0,0 @@
-"""
-Know more, visit 莫烦Python: https://morvanzhou.github.io/tutorials/
-My Youtube Channel: https://www.youtube.com/user/MorvanZhou
-
-Dependencies:
-torch: 0.1.11
-gym: 0.8.1
-numpy
-"""
-import torch
-import torch.nn as nn
-from torch.autograd import Variable
-import torch.nn.functional as F
-import numpy as np
-import gym
-
-# Hyper Parameters
-BATCH_SIZE = 32
-LR = 0.01 # learning rate
-EPSILON = 0.9 # greedy policy
-GAMMA = 0.9 # reward discount
-TARGET_REPLACE_ITER = 100 # target update frequency
-MEMORY_CAPACITY = 2000
-env = gym.make('CartPole-v0')
-env = env.unwrapped
-N_ACTIONS = env.action_space.n
-N_STATES = env.observation_space.shape[0]
-
-
-class Net(nn.Module):
- def __init__(self, ):
- super(Net, self).__init__()
- self.fc1 = nn.Linear(N_STATES, 10)
- self.fc1.weight.data.normal_(0, 0.1) # initialization
- self.out = nn.Linear(10, N_ACTIONS)
- self.out.weight.data.normal_(0, 0.1) # initialization
-
- def forward(self, x):
- x = self.fc1(x)
- x = F.relu(x)
- actions_value = self.out(x)
- return actions_value
-
-
-class DQN(object):
- def __init__(self):
- self.eval_net, self.target_net = Net(), Net()
-
- self.learn_step_counter = 0 # for target updateing
- self.memory_counter = 0 # for storing memory
- self.memory = np.zeros((MEMORY_CAPACITY, N_STATES * 2 + 2)) # initialize memory
- self.optimizer = torch.optim.Adam(self.eval_net.parameters(), lr=LR)
- self.loss_func = nn.MSELoss()
-
- def choose_action(self, x):
- x = Variable(torch.unsqueeze(torch.FloatTensor(x), 0))
- # input only one sample
- if np.random.uniform() < EPSILON: # greedy
- actions_value = self.eval_net.forward(x)
- action = torch.max(actions_value, 1)[1].data.numpy()[0, 0] # return the argmax
- else: # random
- action = np.random.randint(0, N_ACTIONS)
- return action
-
- def store_transition(self, s, a, r, s_):
- transition = np.hstack((s, [a, r], s_))
- # replace the old memory with new memory
- index = self.memory_counter % MEMORY_CAPACITY
- self.memory[index, :] = transition
- self.memory_counter += 1
-
- def learn(self):
- # target parameter update
- if self.learn_step_counter % TARGET_REPLACE_ITER == 0:
- self.target_net.load_state_dict(self.eval_net.state_dict())
-
- # sample batch transitions
- sample_index = np.random.choice(MEMORY_CAPACITY, BATCH_SIZE)
- b_memory = self.memory[sample_index, :]
- b_s = Variable(torch.FloatTensor(b_memory[:, :N_STATES]))
- b_a = Variable(torch.LongTensor(b_memory[:, N_STATES:N_STATES+1].astype(int)))
- b_r = Variable(torch.FloatTensor(b_memory[:, N_STATES+1:N_STATES+2]))
- b_s_ = Variable(torch.FloatTensor(b_memory[:, -N_STATES:]))
-
- # q_eval w.r.t the action in experience
- q_eval = self.eval_net(b_s).gather(1, b_a) # shape (batch, 1)
- q_next = self.target_net(b_s_).detach() # detach from graph, don't backpropagate
- q_target = b_r + GAMMA * q_next.max(1)[0] # shape (batch, 1)
- loss = self.loss_func(q_eval, q_target)
-
- self.optimizer.zero_grad()
- loss.backward()
- self.optimizer.step()
-
-dqn = DQN()
-
-print('\nCollecting experience...')
-for i_episode in range(400):
- s = env.reset()
- ep_r = 0
- while True:
- env.render()
-
- a = dqn.choose_action(s)
-
- # take action
- s_, r, done, info = env.step(a)
-
- # modify the reward
- x, x_dot, theta, theta_dot = s_
- r1 = (env.x_threshold - abs(x)) / env.x_threshold - 0.8
- r2 = (env.theta_threshold_radians - abs(theta)) / env.theta_threshold_radians - 0.5
- r = r1 + r2
-
- # store experience
- dqn.store_transition(s, a, r, s_)
-
- ep_r += r
- if dqn.memory_counter > MEMORY_CAPACITY:
- dqn.learn()
- if done:
- print('Ep: ', i_episode,
- '| Ep_r: ', round(ep_r, 2),
- )
-
- if done:
- break
-
- s = s_
\ No newline at end of file
diff --git a/501_why_torch_dynamic_graph.py b/501_why_torch_dynamic_graph.py
deleted file mode 100644
index 6e42c9e..0000000
--- a/501_why_torch_dynamic_graph.py
+++ /dev/null
@@ -1,106 +0,0 @@
-"""
-Know more, visit 莫烦Python: https://morvanzhou.github.io/tutorials/
-My Youtube Channel: https://www.youtube.com/user/MorvanZhou
-
-Dependencies:
-torch: 0.1.11
-matplotlib
-numpy
-"""
-import torch
-from torch import nn
-from torch.autograd import Variable
-import numpy as np
-import matplotlib.pyplot as plt
-
-torch.manual_seed(1) # reproducible
-
-# Hyper Parameters
-BATCH_SIZE = 64
-TIME_STEP = 5 # rnn time step / image height
-INPUT_SIZE = 1 # rnn input size / image width
-LR = 0.02 # learning rate
-DOWNLOAD_MNIST = False # set to True if haven't download the data
-
-
-class RNN(nn.Module):
- def __init__(self):
- super(RNN, self).__init__()
-
- self.rnn = nn.RNN(
- input_size=1,
- hidden_size=32, # rnn hidden unit
- num_layers=1, # number of rnn layer
- batch_first=True, # input & output will has batch size as 1s dimension. e.g. (batch, time_step, input_size)
- )
- self.out = nn.Linear(32, 1)
-
- def forward(self, x, h_state):
- # x (batch, time_step, input_size)
- # h_state (n_layers, batch, hidden_size)
- # r_out (batch, time_step, output_size)
- r_out, h_state = self.rnn(x, h_state)
-
- outs = [] # this is where you can find torch is dynamic
- for time_step in range(r_out.size(1)): # calculate output for each time step
- outs.append(self.out(r_out[:, time_step, :]))
- return torch.stack(outs, dim=1), h_state
-
-
-rnn = RNN()
-print(rnn)
-
-optimizer = torch.optim.Adam(rnn.parameters(), lr=LR) # optimize all cnn parameters
-loss_func = nn.MSELoss() # the target label is not one-hotted
-
-h_state = None # for initial hidden state
-
-plt.figure(1, figsize=(12, 5))
-plt.ion() # continuously plot
-plt.show()
-
-######################## Below is different #########################
-
-################ static time steps ##########
-# for step in range(60):
-# start, end = step * np.pi, (step+1)*np.pi # time steps
-# # use sin predicts cos
-# steps = np.linspace(start, end, 10, dtype=np.float32)
-
-################ dynamic time steps #########
-step = 0
-for i in range(60):
- dynamic_steps = np.random.randint(1, 4) # has random time steps
- start, end = step * np.pi, (step + dynamic_steps) * np.pi # different time steps length
- step += dynamic_steps
-
- # use sin predicts cos
- steps = np.linspace(start, end, 10 * dynamic_steps, dtype=np.float32)
-
-####################### Above is different ###########################
-
- print(len(steps)) # print how many time step feed to RNN
-
- x_np = np.sin(steps) # float32 for converting torch FloatTensor
- y_np = np.cos(steps)
-
- x = Variable(torch.from_numpy(x_np[np.newaxis, :, np.newaxis])) # shape (batch, time_step, input_size)
- y = Variable(torch.from_numpy(y_np[np.newaxis, :, np.newaxis]))
-
- prediction, h_state = rnn(x, h_state) # rnn output
- # !! next step is important !!
- h_state = Variable(h_state.data) # repack the hidden state, break the connection from last iteration
-
- loss = loss_func(prediction, y) # cross entropy loss
- optimizer.zero_grad() # clear gradients for this training step
- loss.backward() # backpropagation, compute gradients
- optimizer.step() # apply gradients
-
- # plotting
- plt.plot(steps, y_np.flatten(), 'r-')
- plt.plot(steps, prediction.data.numpy().flatten(), 'b-')
- plt.draw()
- plt.pause(0.05)
-
-plt.ioff()
-plt.show()
diff --git a/502_GPU.py b/502_GPU.py
deleted file mode 100644
index 9581f20..0000000
--- a/502_GPU.py
+++ /dev/null
@@ -1,84 +0,0 @@
-"""
-Know more, visit 莫烦Python: https://morvanzhou.github.io/tutorials/
-My Youtube Channel: https://www.youtube.com/user/MorvanZhou
-
-Dependencies:
-torch: 0.1.11
-torchvision
-"""
-import torch
-import torch.nn as nn
-from torch.autograd import Variable
-import torch.utils.data as Data
-import torchvision
-
-torch.manual_seed(1)
-
-EPOCH = 1
-BATCH_SIZE = 50
-LR = 0.001
-DOWNLOAD_MNIST = False
-
-train_data = torchvision.datasets.MNIST(root='./mnist/', train=True, transform=torchvision.transforms.ToTensor(), download=DOWNLOAD_MNIST,)
-train_loader = Data.DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)
-
-test_data = torchvision.datasets.MNIST(root='./mnist/', train=False)
-
-# !!!!!!!! Change in here !!!!!!!!! #
-test_x = Variable(torch.unsqueeze(test_data.test_data, dim=1)).type(torch.FloatTensor)[:2000].cuda()/255. # Tensor on GPU
-test_y = test_data.test_labels[:2000]
-
-
-class CNN(nn.Module):
- def __init__(self):
- super(CNN, self).__init__()
- self.conv1 = nn.Sequential(nn.Conv2d(in_channels=1, out_channels=16, kernel_size=5, stride=1, padding=2,),
- nn.ReLU(), nn.MaxPool2d(kernel_size=2),)
- self.conv2 = nn.Sequential(nn.Conv2d(16, 32, 5, 1, 2), nn.ReLU(), nn.MaxPool2d(2),)
- self.out = nn.Linear(32 * 7 * 7, 10)
-
- def forward(self, x):
- x = self.conv1(x)
- x = self.conv2(x)
- x = x.view(x.size(0), -1)
- output = self.out(x)
- return output
-
-cnn = CNN()
-
-# !!!!!!!! Change in here !!!!!!!!! #
-cnn.cuda() # Moves all model parameters and buffers to the GPU.
-
-optimizer = torch.optim.Adam(cnn.parameters(), lr=LR)
-loss_func = nn.CrossEntropyLoss()
-
-for epoch in range(EPOCH):
- for step, (x, y) in enumerate(train_loader):
-
- # !!!!!!!! Change in here !!!!!!!!! #
- b_x = Variable(x).cuda() # Tensor on GPU
- b_y = Variable(y).cuda() # Tensor on GPU
-
- output = cnn(b_x)
- loss = loss_func(output, b_y)
- optimizer.zero_grad()
- loss.backward()
- optimizer.step()
-
- if step % 50 == 0:
- test_output = cnn(test_x)
-
- # !!!!!!!! Change in here !!!!!!!!! #
- pred_y = torch.max(test_output, 1)[1].cup().data.squeeze() # Move to CPU
-
- accuracy = sum(pred_y == test_y) / test_y.size(0)
- print('Epoch: ', epoch, '| train loss: %.4f' % loss.data[0], '| test accuracy: %.2f' % accuracy)
-
-
-test_output = cnn(test_x[:10])
-
-# !!!!!!!! Change in here !!!!!!!!! #
-pred_y = torch.max(test_output, 1)[1].cup().data.numpy().squeeze() # Move to CPU
-
-print(pred_y, 'prediction number')
-print(test_y[:10].numpy(), 'real number')
diff --git a/503_dropout.py b/503_dropout.py
deleted file mode 100644
index 3f4f42f..0000000
--- a/503_dropout.py
+++ /dev/null
@@ -1,100 +0,0 @@
-"""
-Know more, visit 莫烦Python: https://morvanzhou.github.io/tutorials/
-My Youtube Channel: https://www.youtube.com/user/MorvanZhou
-
-Dependencies:
-torch: 0.1.11
-matplotlib
-"""
-import torch
-from torch.autograd import Variable
-import matplotlib.pyplot as plt
-
-torch.manual_seed(1) # reproducible
-
-N_SAMPLES = 20
-N_HIDDEN = 300
-
-# training data
-x = torch.unsqueeze(torch.linspace(-1, 1, N_SAMPLES), 1)
-y = x + 0.3*torch.normal(torch.zeros(N_SAMPLES, 1), torch.ones(N_SAMPLES, 1))
-x, y = Variable(x), Variable(y)
-
-# test data
-test_x = torch.unsqueeze(torch.linspace(-1, 1, N_SAMPLES), 1)
-test_y = test_x + 0.3*torch.normal(torch.zeros(N_SAMPLES, 1), torch.ones(N_SAMPLES, 1))
-test_x, test_y = Variable(test_x, volatile=True), Variable(test_y, volatile=True)
-
-# show data
-plt.scatter(x.data.numpy(), y.data.numpy(), c='magenta', s=50, alpha=0.5, label='train')
-plt.scatter(test_x.data.numpy(), test_y.data.numpy(), c='cyan', s=50, alpha=0.5, label='test')
-plt.legend(loc='upper left')
-plt.ylim((-2.5, 2.5))
-plt.show()
-
-net_overfitting = torch.nn.Sequential(
- torch.nn.Linear(1, N_HIDDEN),
- torch.nn.ReLU(),
- torch.nn.Linear(N_HIDDEN, N_HIDDEN),
- torch.nn.ReLU(),
- torch.nn.Linear(N_HIDDEN, 1),
-)
-
-net_dropped = torch.nn.Sequential(
- torch.nn.Linear(1, N_HIDDEN),
- torch.nn.Dropout(0.5), # drop 50% of the neuron
- torch.nn.ReLU(),
- torch.nn.Linear(N_HIDDEN, N_HIDDEN),
- torch.nn.Dropout(0.5), # drop 50% of the neuron
- torch.nn.ReLU(),
- torch.nn.Linear(N_HIDDEN, 1),
-)
-
-print(net_overfitting) # net architecture
-print(net_dropped)
-
-optimizer_ofit = torch.optim.Adam(net_overfitting.parameters(), lr=0.01)
-optimizer_drop = torch.optim.Adam(net_dropped.parameters(), lr=0.01)
-loss_func = torch.nn.MSELoss()
-
-plt.ion() # something about plotting
-plt.show()
-
-for t in range(500):
- pred_ofit = net_overfitting(x)
- pred_drop = net_dropped(x)
- loss_ofit = loss_func(pred_ofit, y)
- loss_drop = loss_func(pred_drop, y)
-
- optimizer_ofit.zero_grad()
- optimizer_drop.zero_grad()
- loss_ofit.backward()
- loss_drop.backward()
- optimizer_ofit.step()
- optimizer_drop.step()
-
- if t % 10 == 0:
- # change to eval mode in order to fix drop out effect
- net_overfitting.eval()
- net_dropped.eval() # parameters for dropout differ from train mode
-
- # plotting
- plt.cla()
- test_pred_ofit = net_overfitting(test_x)
- test_pred_drop = net_dropped(test_x)
- plt.scatter(x.data.numpy(), y.data.numpy(), c='magenta', s=50, alpha=0.3, label='train')
- plt.scatter(test_x.data.numpy(), test_y.data.numpy(), c='cyan', s=50, alpha=0.3, label='test')
- plt.plot(test_x.data.numpy(), test_pred_ofit.data.numpy(), 'r-', lw=3, label='overfitting')
- plt.plot(test_x.data.numpy(), test_pred_drop.data.numpy(), 'b--', lw=3, label='dropout(50%)')
- plt.text(0, -1.2, 'overfitting loss=%.4f' % loss_func(test_pred_ofit, test_y).data[0], fontdict={'size': 20, 'color': 'red'})
- plt.text(0, -1.5, 'dropout loss=%.4f' % loss_func(test_pred_drop, test_y).data[0], fontdict={'size': 20, 'color': 'blue'})
- plt.legend(loc='upper left')
- plt.ylim((-2.5, 2.5))
- plt.pause(0.1)
-
- # change back to train mode
- net_overfitting.train()
- net_dropped.train()
-
-plt.ioff()
-plt.show()
\ No newline at end of file
diff --git a/504_batch_normalization.py b/504_batch_normalization.py
deleted file mode 100644
index e4bd046..0000000
--- a/504_batch_normalization.py
+++ /dev/null
@@ -1,173 +0,0 @@
-"""
-Know more, visit 莫烦Python: https://morvanzhou.github.io/tutorials/
-My Youtube Channel: https://www.youtube.com/user/MorvanZhou
-
-Dependencies:
-torch: 0.1.11
-matplotlib
-numpy
-"""
-import torch
-from torch.autograd import Variable
-from torch import nn
-from torch.nn import init
-import torch.utils.data as Data
-import torch.nn.functional as F
-import matplotlib.pyplot as plt
-import numpy as np
-
-torch.manual_seed(1) # reproducible
-np.random.seed(1)
-
-# Hyper parameters
-N_SAMPLES = 2000
-BATCH_SIZE = 64
-EPOCH = 12
-LR = 0.03
-N_HIDDEN = 8
-ACTIVATION = F.tanh
-B_INIT = -0.2 # use a bad bias constant initializer
-
-# training data
-x = np.linspace(-7, 10, N_SAMPLES)[:, np.newaxis]
-noise = np.random.normal(0, 2, x.shape)
-y = np.square(x) - 5 + noise
-
-# test data
-test_x = np.linspace(-7, 10, 200)[:, np.newaxis]
-noise = np.random.normal(0, 2, test_x.shape)
-test_y = np.square(test_x) - 5 + noise
-
-train_x, train_y = torch.from_numpy(x).float(), torch.from_numpy(y).float()
-test_x = Variable(torch.from_numpy(test_x).float(), volatile=True) # not for computing gradients
-test_y = Variable(torch.from_numpy(test_y).float(), volatile=True)
-
-train_dataset = Data.TensorDataset(data_tensor=train_x, target_tensor=train_y)
-train_loader = Data.DataLoader(dataset=train_dataset, batch_size=BATCH_SIZE, shuffle=True, num_workers=2,)
-
-# show data
-plt.scatter(train_x.numpy(), train_y.numpy(), c='#FF9359', s=50, alpha=0.2, label='train')
-plt.legend(loc='upper left')
-plt.show()
-
-class Net(nn.Module):
- def __init__(self, batch_normalization=False):
- super(Net, self).__init__()
- self.do_bn = batch_normalization
- self.fcs = []
- self.bns = []
- self.bn_input = nn.BatchNorm1d(1, momentum=0.5) # for input data
-
- for i in range(N_HIDDEN): # build hidden layers and BN layers
- input_size = 1 if i == 0 else 10
- fc = nn.Linear(input_size, 10)
- setattr(self, 'fc%i' % i, fc) # IMPORTANT set layer to the Module
- self._set_init(fc) # parameters initialization
- self.fcs.append(fc)
- if self.do_bn:
- bn = nn.BatchNorm1d(10, momentum=0.5)
- setattr(self, 'bn%i' % i, bn) # IMPORTANT set layer to the Module
- self.bns.append(bn)
-
- self.predict = nn.Linear(10, 1) # output layer
- self._set_init(self.predict) # parameters initialization
-
- def _set_init(self, layer):
- init.normal(layer.weight, mean=0., std=.1)
- init.constant(layer.bias, B_INIT)
-
- def forward(self, x):
- pre_activation = [x]
- if self.do_bn: x = self.bn_input(x) # input batch normalization
- layer_input = [x]
- for i in range(N_HIDDEN):
- x = self.fcs[i](x)
- pre_activation.append(x)
- if self.do_bn: x = self.bns[i](x) # batch normalization
- x = ACTIVATION(x)
- layer_input.append(x)
- out = self.predict(x)
- return out, layer_input, pre_activation
-
-nets = [Net(batch_normalization=False), Net(batch_normalization=True)]
-
-print(*nets) # print net architecture
-
-opts = [torch.optim.Adam(net.parameters(), lr=LR) for net in nets]
-
-loss_func = torch.nn.MSELoss()
-
-f, axs = plt.subplots(4, N_HIDDEN+1, figsize=(10, 5))
-plt.ion() # something about plotting
-plt.show()
-
-def plot_histogram(l_in, l_in_bn, pre_ac, pre_ac_bn):
- for i, (ax_pa, ax_pa_bn, ax, ax_bn) in enumerate(zip(axs[0, :], axs[1, :], axs[2, :], axs[3, :])):
- [a.clear() for a in [ax_pa, ax_pa_bn, ax, ax_bn]]
- if i == 0:
- p_range = (-7, 10)
- the_range = (-7, 10)
- else:
- p_range = (-4, 4)
- the_range = (-1, 1)
- ax_pa.set_title('L' + str(i))
- ax_pa.hist(pre_ac[i].data.numpy().ravel(), bins=10, range=p_range, color='#FF9359', alpha=0.5)
- ax_pa_bn.hist(pre_ac_bn[i].data.numpy().ravel(), bins=10, range=p_range, color='#74BCFF', alpha=0.5)
- ax.hist(l_in[i].data.numpy().ravel(), bins=10, range=the_range, color='#FF9359')
- ax_bn.hist(l_in_bn[i].data.numpy().ravel(), bins=10, range=the_range, color='#74BCFF')
- for a in [ax_pa, ax, ax_pa_bn, ax_bn]:
- a.set_yticks(())
- a.set_xticks(())
- ax_pa_bn.set_xticks(p_range)
- ax_bn.set_xticks(the_range)
- axs[0, 0].set_ylabel('PreAct')
- axs[1, 0].set_ylabel('BN PreAct')
- axs[2, 0].set_ylabel('Act')
- axs[3, 0].set_ylabel('BN Act')
- plt.pause(0.01)
-
-# training
-losses = [[], []] # recode loss for two networks
-for epoch in range(EPOCH):
- print('Epoch: ', epoch)
- layer_inputs, pre_acts = [], []
- for net, l in zip(nets, losses):
- net.eval() # set eval mode to fix moving_mean and moving_var
- pred, layer_input, pre_act = net(test_x)
- l.append(loss_func(pred, test_y).data[0])
- layer_inputs.append(layer_input)
- pre_acts.append(pre_act)
- net.train() # free moving_mean and moving_var
- plot_histogram(*layer_inputs, *pre_acts) # plot histogram
-
- for step, (b_x, b_y) in enumerate(train_loader):
- b_x, b_y = Variable(b_x), Variable(b_y)
- for net, opt in zip(nets, opts): # train for each network
- pred, _, _ = net(b_x)
- loss = loss_func(pred, b_y)
- opt.zero_grad()
- loss.backward()
- opt.step() # it will also learn the parameters in Batch Normalization
-
-
-plt.ioff()
-
-# plot training loss
-plt.figure(2)
-plt.plot(losses[0], c='#FF9359', lw=3, label='Original')
-plt.plot(losses[1], c='#74BCFF', lw=3, label='Batch Normalization')
-plt.xlabel('step')
-plt.ylabel('test loss')
-plt.ylim((0, 2000))
-plt.legend(loc='best')
-
-# evaluation
-# set net to eval mode to freeze the parameters in batch normalization layers
-[net.eval() for net in nets] # set eval mode to fix moving_mean and moving_var
-preds = [net(test_x)[0] for net in nets]
-plt.figure(3)
-plt.plot(test_x.data.numpy(), preds[0].data.numpy(), c='#FF9359', lw=4, label='Original')
-plt.plot(test_x.data.numpy(), preds[1].data.numpy(), c='#74BCFF', lw=4, label='Batch Normalization')
-plt.scatter(test_x.data.numpy(), test_y.data.numpy(), c='r', s=50, alpha=0.2, label='train')
-plt.legend(loc='best')
-plt.show()
diff --git a/README.md b/README.md
index 62363e8..9b968b3 100644
--- a/README.md
+++ b/README.md
@@ -1,6 +1,6 @@
-  +
+ 
@@ -17,63 +17,63 @@ If you speak Chinese, you can watch my [Youtube channel](https://www.youtube.com
* pyTorch basic
- * [torch and numpy](https://github.com/MorvanZhou/tutorials/blob/master/pytorchTUT/201_torch_numpy.py)
- * [Variable](https://github.com/MorvanZhou/tutorials/blob/master/pytorchTUT/202_variable.py)
- * [Activation](https://github.com/MorvanZhou/tutorials/blob/master/pytorchTUT/203_activation.py)
+ * [torch and numpy](https://github.com/MorvanZhou/PyTorch-Tutorial/blob/master/tutorial-contents/201_torch_numpy.py)
+ * [Variable](https://github.com/MorvanZhou/PyTorch-Tutorial/blob/master/tutorial-contents/202_variable.py)
+ * [Activation](https://github.com/MorvanZhou/PyTorch-Tutorial/blob/master/tutorial-contents/203_activation.py)
* Build your first network
- * [Regression](https://github.com/MorvanZhou/tutorials/blob/master/pytorchTUT/301_regression.py)
- * [Classification](https://github.com/MorvanZhou/tutorials/blob/master/pytorchTUT/302_classification.py)
- * [An easy way](https://github.com/MorvanZhou/tutorials/blob/master/pytorchTUT/303_build_nn_quickly.py)
- * [Save and reload](https://github.com/MorvanZhou/tutorials/blob/master/pytorchTUT/304_save_reload.py)
- * [Train on batch](https://github.com/MorvanZhou/tutorials/blob/master/pytorchTUT/305_batch_train.py)
- * [Optimizers](https://github.com/MorvanZhou/tutorials/blob/master/pytorchTUT/306_optimizer.py)
+ * [Regression](https://github.com/MorvanZhou/PyTorch-Tutorial/blob/master/tutorial-contents/301_regression.py)
+ * [Classification](https://github.com/MorvanZhou/PyTorch-Tutorial/blob/master/tutorial-contents/302_classification.py)
+ * [An easy way](https://github.com/MorvanZhou/PyTorch-Tutorial/blob/master/tutorial-contents/303_build_nn_quickly.py)
+ * [Save and reload](https://github.com/MorvanZhou/PyTorch-Tutorial/blob/master/tutorial-contents/304_save_reload.py)
+ * [Train on batch](https://github.com/MorvanZhou/PyTorch-Tutorial/blob/master/tutorial-contents/305_batch_train.py)
+ * [Optimizers](https://github.com/MorvanZhou/PyTorch-Tutorial/blob/master/tutorial-contents/306_optimizer.py)
* Advanced neural network
- * [CNN](https://github.com/MorvanZhou/tutorials/blob/master/pytorchTUT/401_CNN.py)
- * [RNN-Classification](https://github.com/MorvanZhou/tutorials/blob/master/pytorchTUT/402_RNN_classifier.py)
- * [RNN-Regression](https://github.com/MorvanZhou/tutorials/blob/master/pytorchTUT/403_RNN_regressor.py)
- * [AutoEncoder](https://github.com/MorvanZhou/tutorials/blob/master/pytorchTUT/404_autoencoder.py)
- * [DQN Reinforcement Learning](https://github.com/MorvanZhou/tutorials/blob/master/pytorchTUT/405_DQN_Reinforcement_learning.py)
+ * [CNN](https://github.com/MorvanZhou/PyTorch-Tutorial/blob/master/tutorial-contents/401_CNN.py)
+ * [RNN-Classification](https://github.com/MorvanZhou/PyTorch-Tutorial/blob/master/tutorial-contents/402_RNN_classifier.py)
+ * [RNN-Regression](https://github.com/MorvanZhou/PyTorch-Tutorial/blob/master/tutorial-contents/403_RNN_regressor.py)
+ * [AutoEncoder](https://github.com/MorvanZhou/PyTorch-Tutorial/blob/master/tutorial-contents/404_autoencoder.py)
+ * [DQN Reinforcement Learning](https://github.com/MorvanZhou/PyTorch-Tutorial/blob/master/tutorial-contents/405_DQN_Reinforcement_learning.py)
* Others (WIP)
- * [Why torch dynamic](https://github.com/MorvanZhou/tutorials/blob/master/pytorchTUT/501_why_torch_dynamic_graph.py)
- * [Train on GPU](https://github.com/MorvanZhou/tutorials/blob/master/pytorchTUT/502_GPU.py)
- * [Dropout](https://github.com/MorvanZhou/tutorials/blob/master/pytorchTUT/503_dropout.py)
- * [Batch Normalization](https://github.com/MorvanZhou/tutorials/blob/master/pytorchTUT/504_batch_normalization.py)
+ * [Why torch dynamic](https://github.com/MorvanZhou/PyTorch-Tutorial/blob/master/tutorial-contents/501_why_torch_dynamic_graph.py)
+ * [Train on GPU](https://github.com/MorvanZhou/PyTorch-Tutorial/blob/master/tutorial-contents/502_GPU.py)
+ * [Dropout](https://github.com/MorvanZhou/PyTorch-Tutorial/blob/master/tutorial-contents/503_dropout.py)
+ * [Batch Normalization](https://github.com/MorvanZhou/PyTorch-Tutorial/blob/master/tutorial-contents/504_batch_normalization.py)
-### [Regression](https://github.com/MorvanZhou/tutorials/blob/master/pytorchTUT/301_regression.py)
+### [Regression](https://github.com/MorvanZhou/PyTorch-Tutorial/blob/master/tutorial-contents/301_regression.py)
-
+
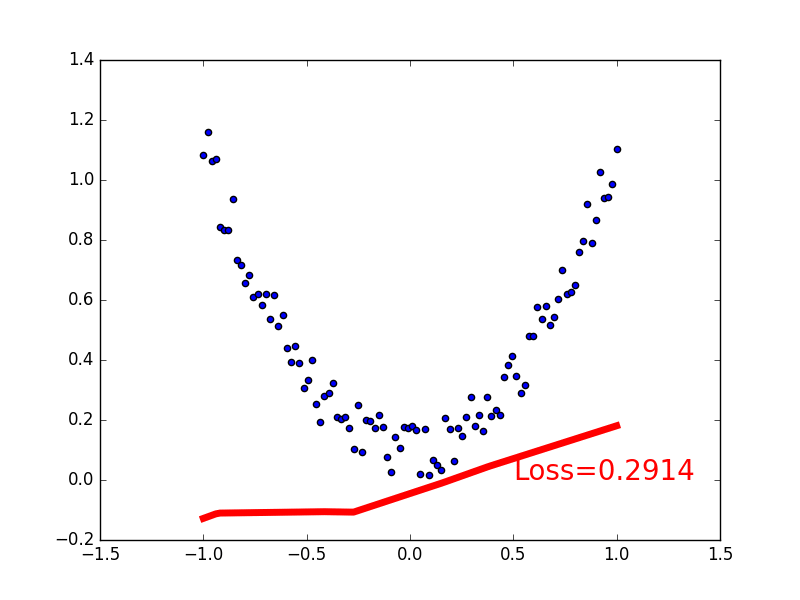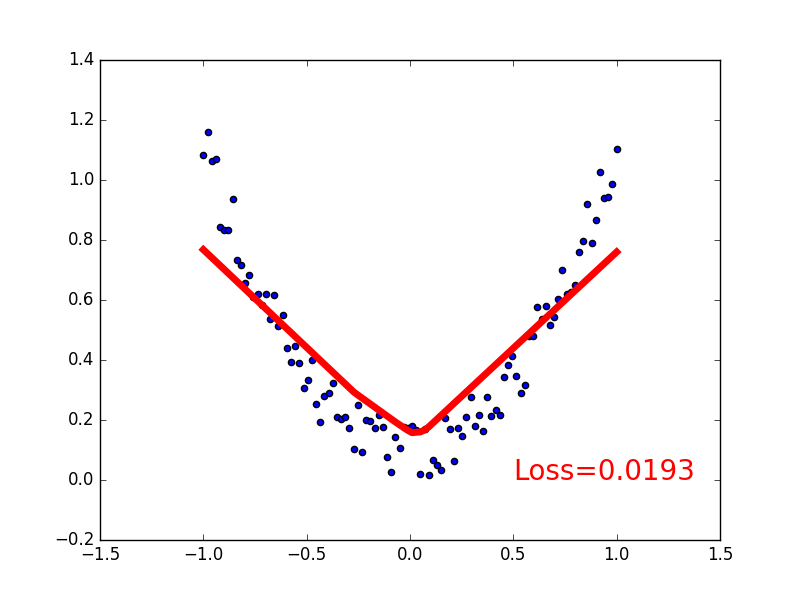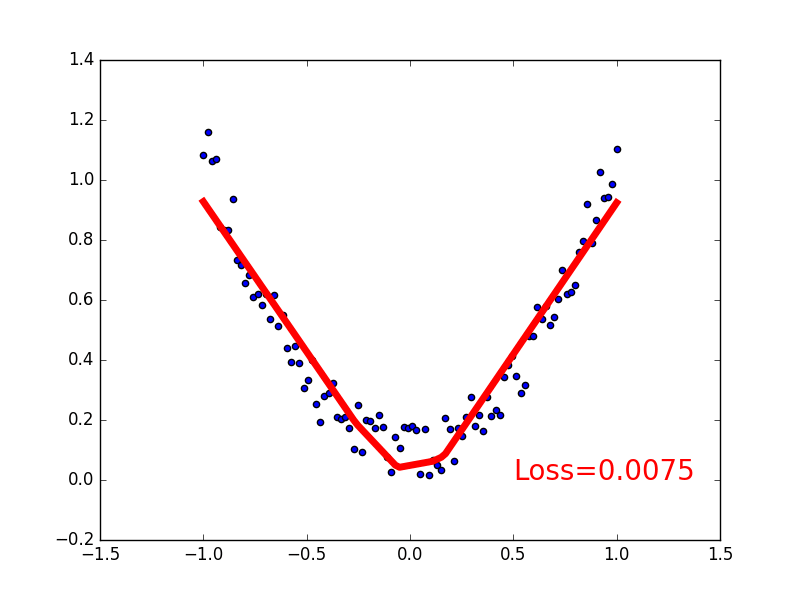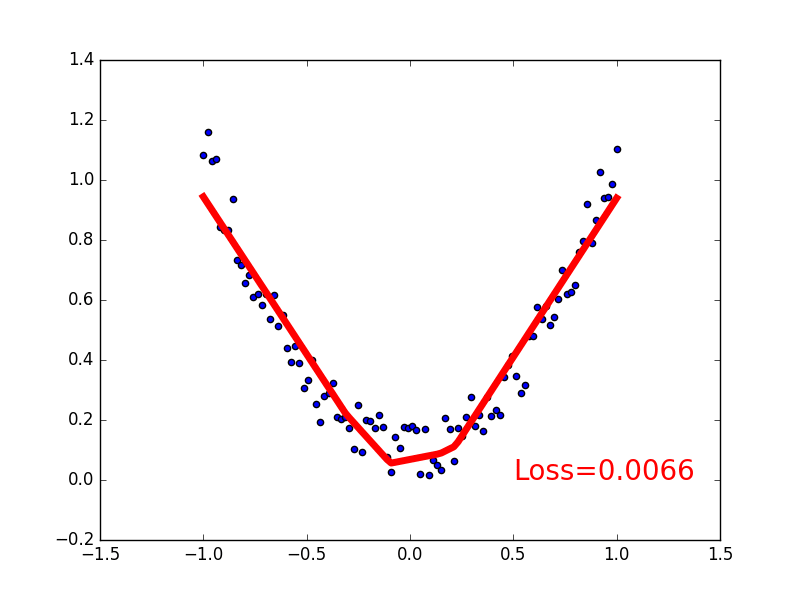 -### [Classification](https://github.com/MorvanZhou/tutorials/blob/master/pytorchTUT/302_classification.py)
+### [Classification](https://github.com/MorvanZhou/PyTorch-Tutorial/blob/master/tutorial-contents/302_classification.py)
-
+
-### [Classification](https://github.com/MorvanZhou/tutorials/blob/master/pytorchTUT/302_classification.py)
+### [Classification](https://github.com/MorvanZhou/PyTorch-Tutorial/blob/master/tutorial-contents/302_classification.py)
-
+
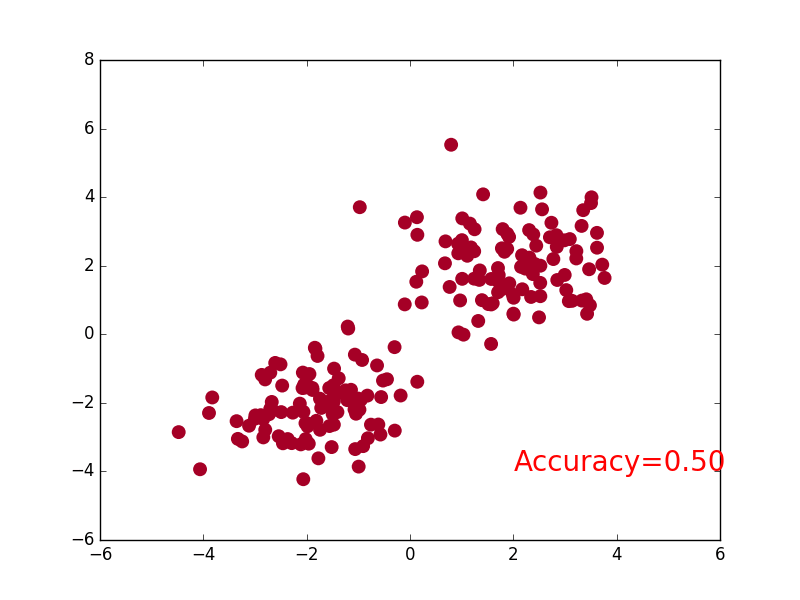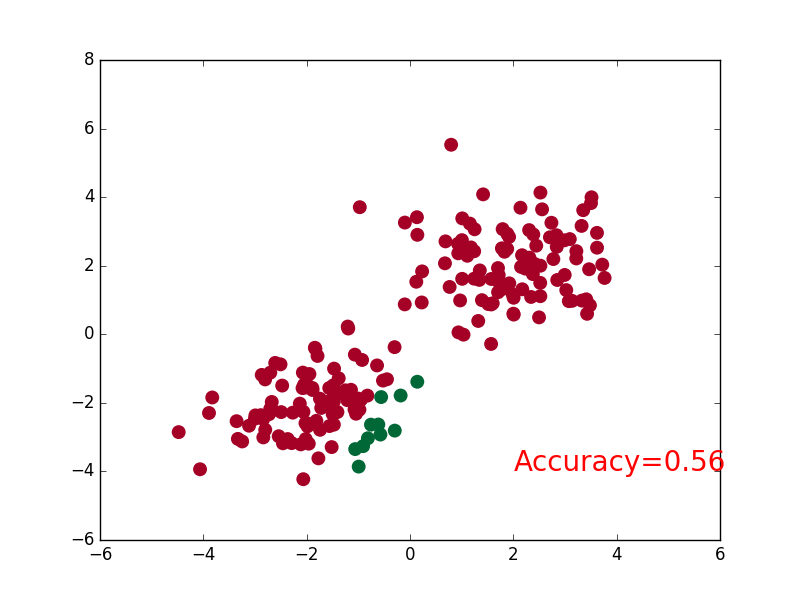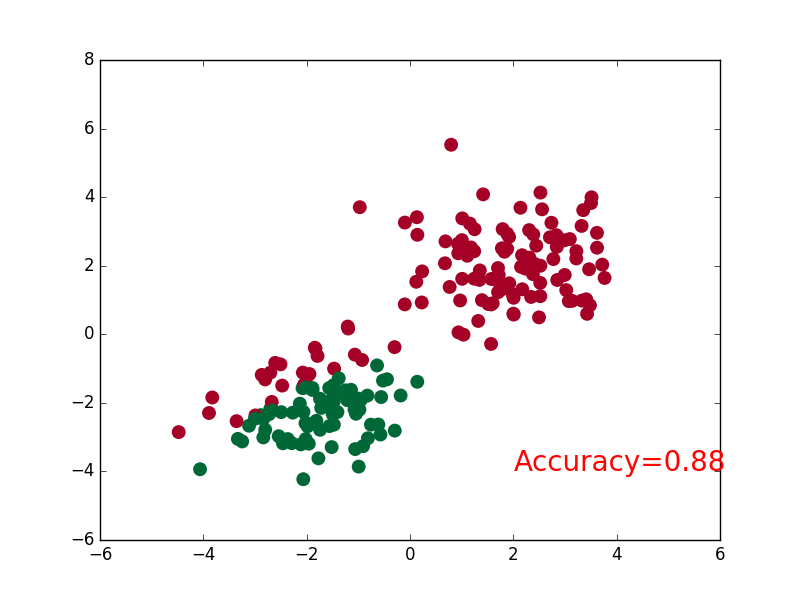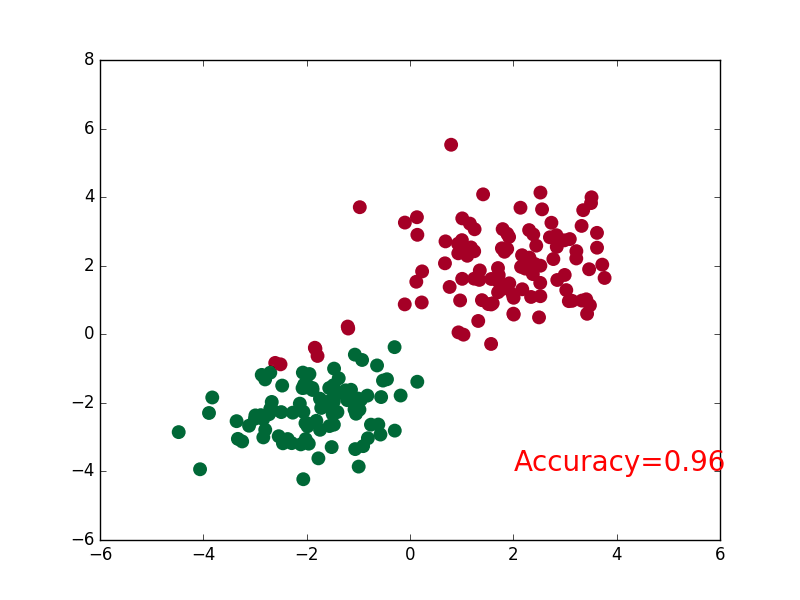 -### [RNN](https://github.com/MorvanZhou/tutorials/blob/master/pytorchTUT/403_RNN_regressor.py)
+### [RNN](https://github.com/MorvanZhou/PyTorch-Tutorial/blob/master/tutorial-contents/403_RNN_regressor.py)
-
+
-### [RNN](https://github.com/MorvanZhou/tutorials/blob/master/pytorchTUT/403_RNN_regressor.py)
+### [RNN](https://github.com/MorvanZhou/PyTorch-Tutorial/blob/master/tutorial-contents/403_RNN_regressor.py)
-
+
 -### [Autoencoder](https://github.com/MorvanZhou/tutorials/blob/master/pytorchTUT/404_autoencoder.py)
+### [Autoencoder](https://github.com/MorvanZhou/PyTorch-Tutorial/blob/master/tutorial-contents/404_autoencoder.py)
-
+
-### [Autoencoder](https://github.com/MorvanZhou/tutorials/blob/master/pytorchTUT/404_autoencoder.py)
+### [Autoencoder](https://github.com/MorvanZhou/PyTorch-Tutorial/blob/master/tutorial-contents/404_autoencoder.py)
-
+
 -
+
-
+
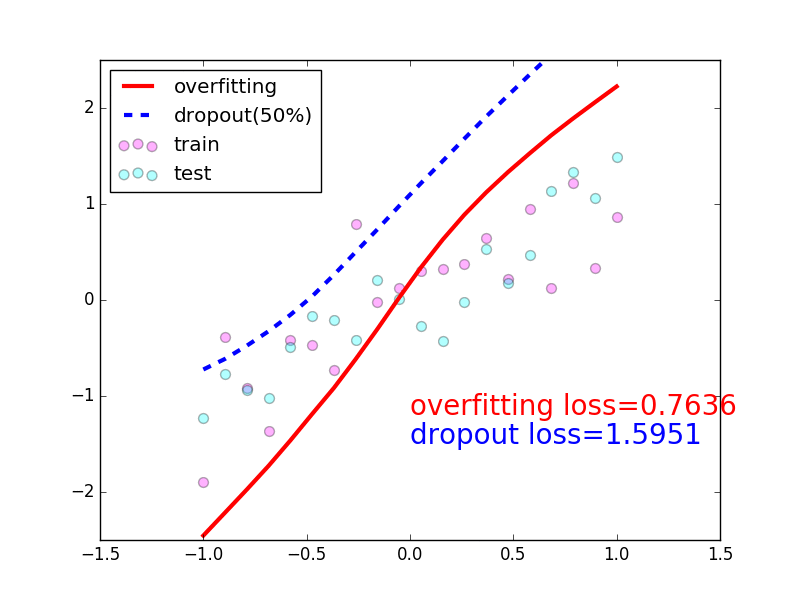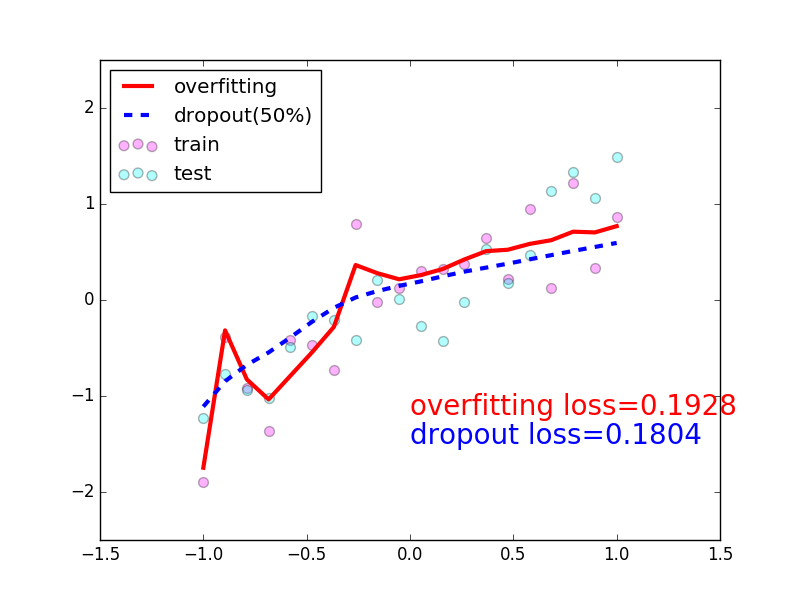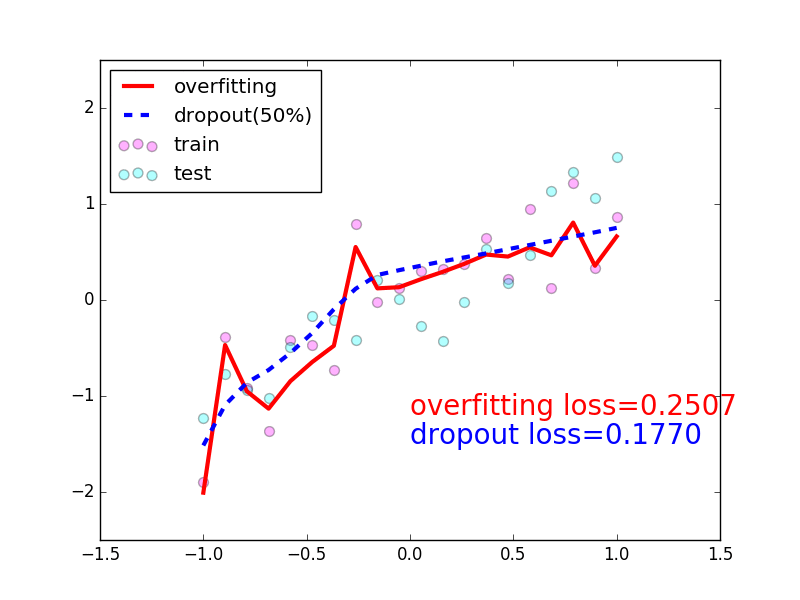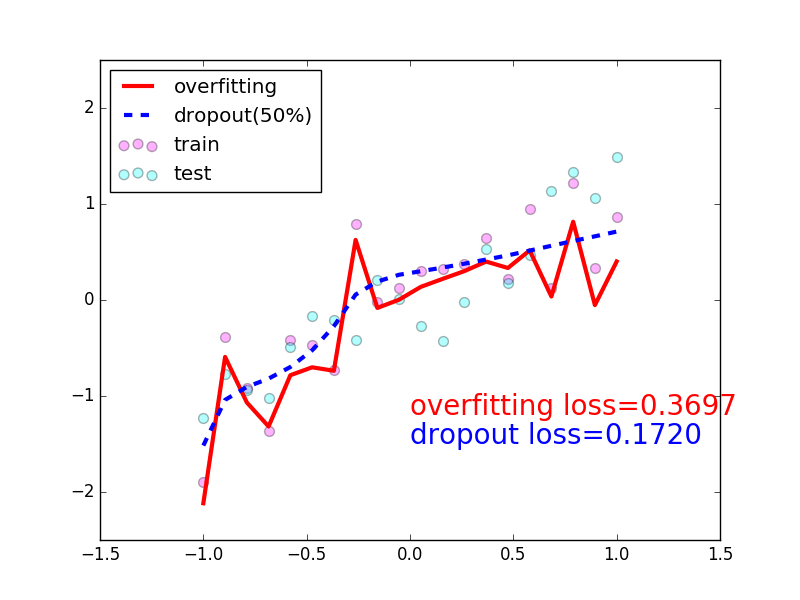
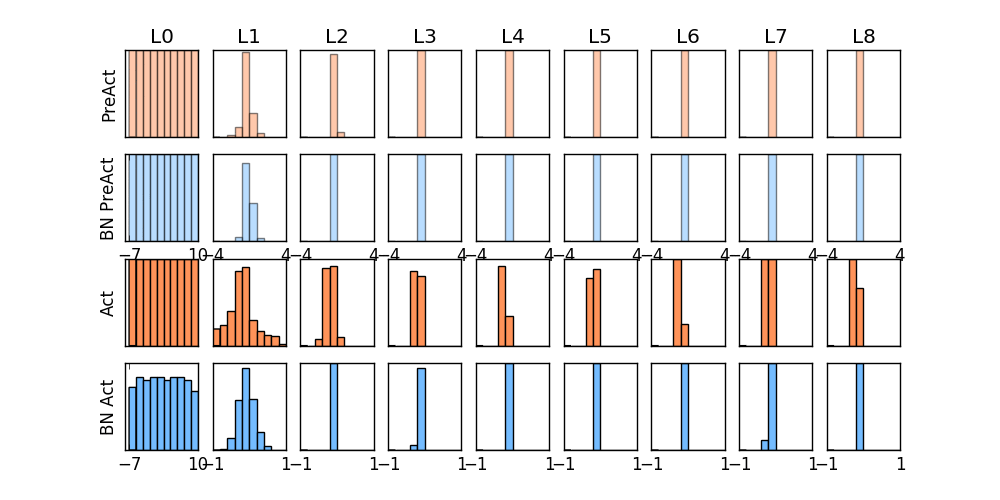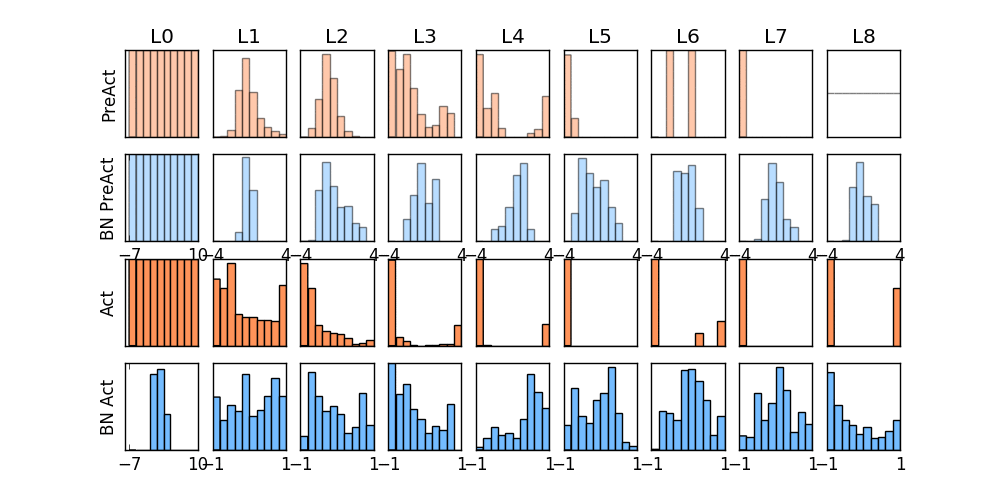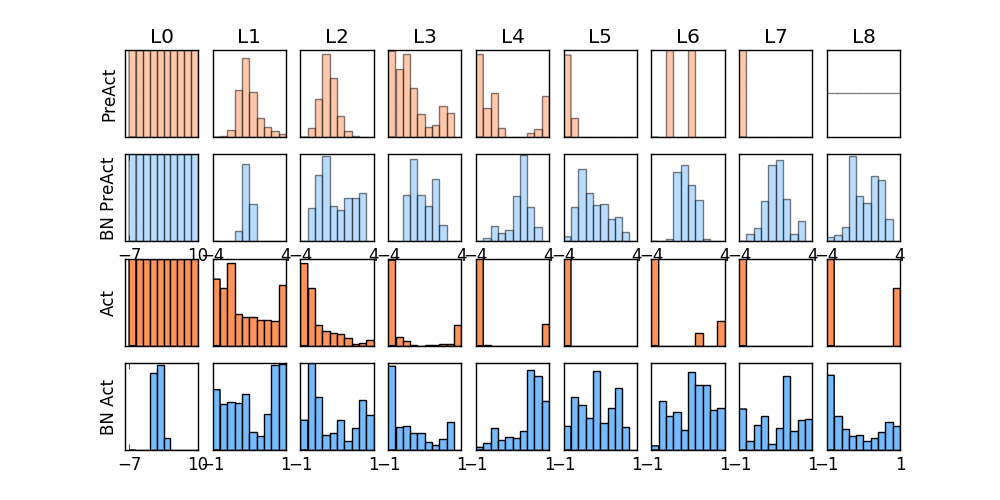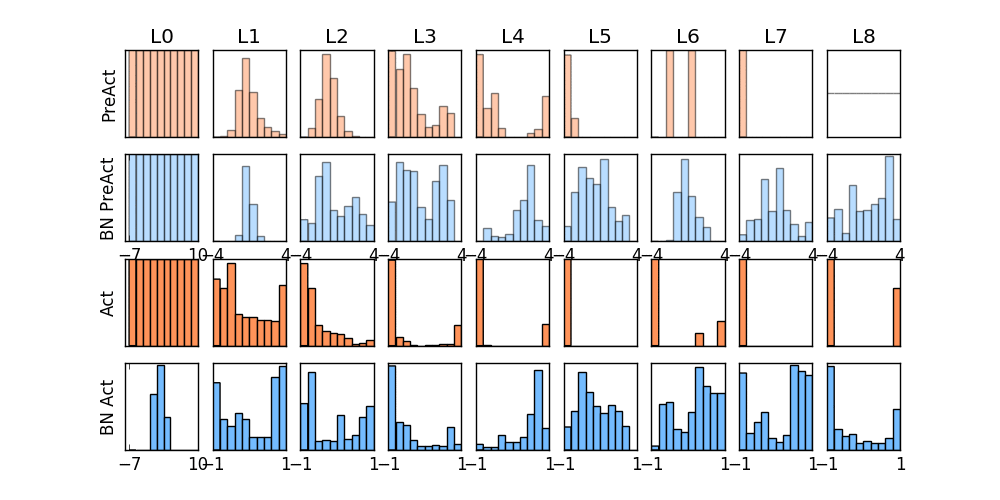
 -### [Dropout](https://github.com/MorvanZhou/tutorials/blob/master/pytorchTUT/503_dropout.py)
-
+### [Dropout](https://github.com/MorvanZhou/PyTorch-Tutorial/blob/master/tutorial-contents/503_dropout.py)
+
-### [Dropout](https://github.com/MorvanZhou/tutorials/blob/master/pytorchTUT/503_dropout.py)
-
+### [Dropout](https://github.com/MorvanZhou/PyTorch-Tutorial/blob/master/tutorial-contents/503_dropout.py)
+
 -### [Batch Normalization](https://github.com/MorvanZhou/tutorials/blob/master/pytorchTUT/504_batch_normalization.py)
-
+### [Batch Normalization](https://github.com/MorvanZhou/PyTorch-Tutorial/blob/master/tutorial-contents/504_batch_normalization.py)
+
-### [Batch Normalization](https://github.com/MorvanZhou/tutorials/blob/master/pytorchTUT/504_batch_normalization.py)
-
+### [Batch Normalization](https://github.com/MorvanZhou/PyTorch-Tutorial/blob/master/tutorial-contents/504_batch_normalization.py)
+
 diff --git a/mnist/processed/test.pt b/mnist/processed/test.pt
deleted file mode 100644
index aa3d55f..0000000
Binary files a/mnist/processed/test.pt and /dev/null differ
diff --git a/mnist/processed/training.pt b/mnist/processed/training.pt
deleted file mode 100644
index ca04bfe..0000000
Binary files a/mnist/processed/training.pt and /dev/null differ
diff --git a/mnist/raw/t10k-images-idx3-ubyte b/mnist/raw/t10k-images-idx3-ubyte
deleted file mode 100644
index 1170b2c..0000000
Binary files a/mnist/raw/t10k-images-idx3-ubyte and /dev/null differ
diff --git a/mnist/raw/t10k-labels-idx1-ubyte b/mnist/raw/t10k-labels-idx1-ubyte
deleted file mode 100644
index d1c3a97..0000000
Binary files a/mnist/raw/t10k-labels-idx1-ubyte and /dev/null differ
diff --git a/mnist/raw/train-images-idx3-ubyte b/mnist/raw/train-images-idx3-ubyte
deleted file mode 100644
index bbce276..0000000
Binary files a/mnist/raw/train-images-idx3-ubyte and /dev/null differ
diff --git a/mnist/raw/train-labels-idx1-ubyte b/mnist/raw/train-labels-idx1-ubyte
deleted file mode 100644
index d6b4c5d..0000000
Binary files a/mnist/raw/train-labels-idx1-ubyte and /dev/null differ
diff --git a/mnist/processed/test.pt b/mnist/processed/test.pt
deleted file mode 100644
index aa3d55f..0000000
Binary files a/mnist/processed/test.pt and /dev/null differ
diff --git a/mnist/processed/training.pt b/mnist/processed/training.pt
deleted file mode 100644
index ca04bfe..0000000
Binary files a/mnist/processed/training.pt and /dev/null differ
diff --git a/mnist/raw/t10k-images-idx3-ubyte b/mnist/raw/t10k-images-idx3-ubyte
deleted file mode 100644
index 1170b2c..0000000
Binary files a/mnist/raw/t10k-images-idx3-ubyte and /dev/null differ
diff --git a/mnist/raw/t10k-labels-idx1-ubyte b/mnist/raw/t10k-labels-idx1-ubyte
deleted file mode 100644
index d1c3a97..0000000
Binary files a/mnist/raw/t10k-labels-idx1-ubyte and /dev/null differ
diff --git a/mnist/raw/train-images-idx3-ubyte b/mnist/raw/train-images-idx3-ubyte
deleted file mode 100644
index bbce276..0000000
Binary files a/mnist/raw/train-images-idx3-ubyte and /dev/null differ
diff --git a/mnist/raw/train-labels-idx1-ubyte b/mnist/raw/train-labels-idx1-ubyte
deleted file mode 100644
index d6b4c5d..0000000
Binary files a/mnist/raw/train-labels-idx1-ubyte and /dev/null differ