diff --git a/README.md b/README.md
index 776726f..9b27aa5 100644
--- a/README.md
+++ b/README.md
@@ -56,6 +56,11 @@ You can watch my [Youtube channel](https://www.youtube.com/channel/UCdyjiB5H8Pu7
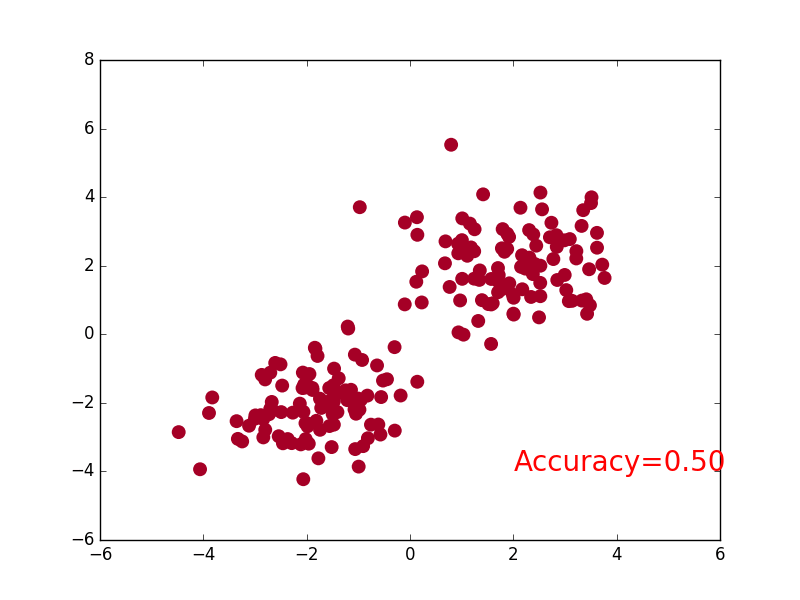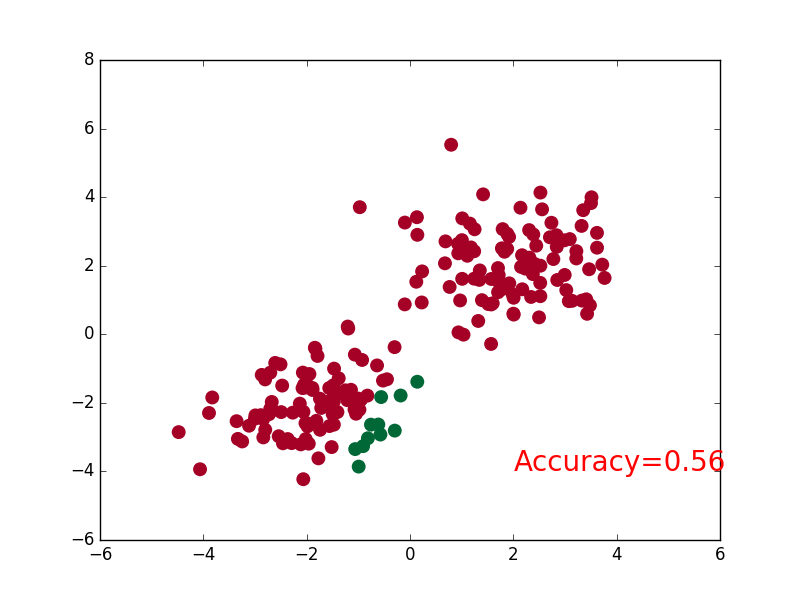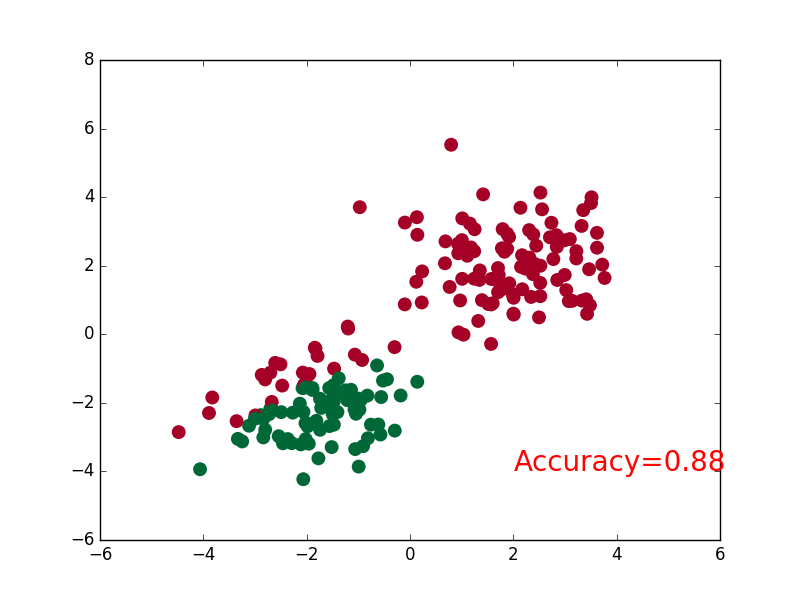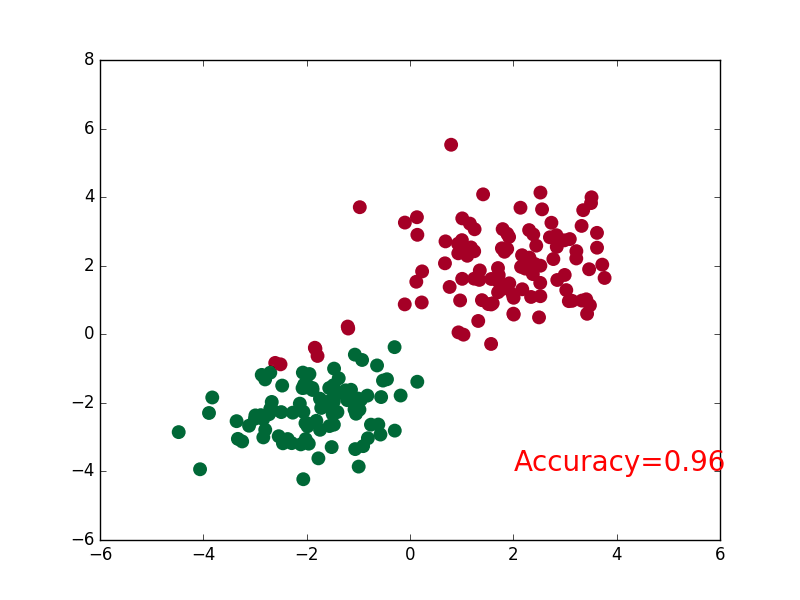 +### [CNN](https://github.com/MorvanZhou/PyTorch-Tutorial/blob/master/tutorial-contents/401_CNN.py)
+
+
+### [CNN](https://github.com/MorvanZhou/PyTorch-Tutorial/blob/master/tutorial-contents/401_CNN.py)
+
+ 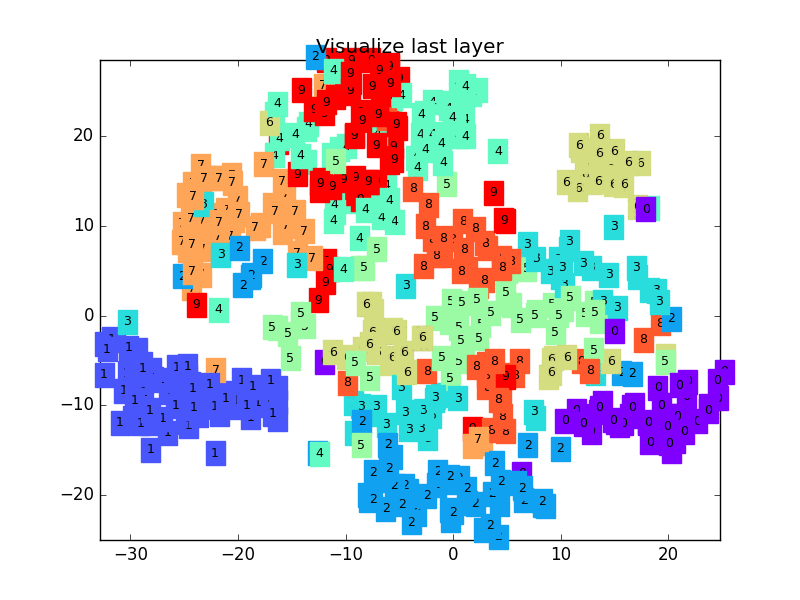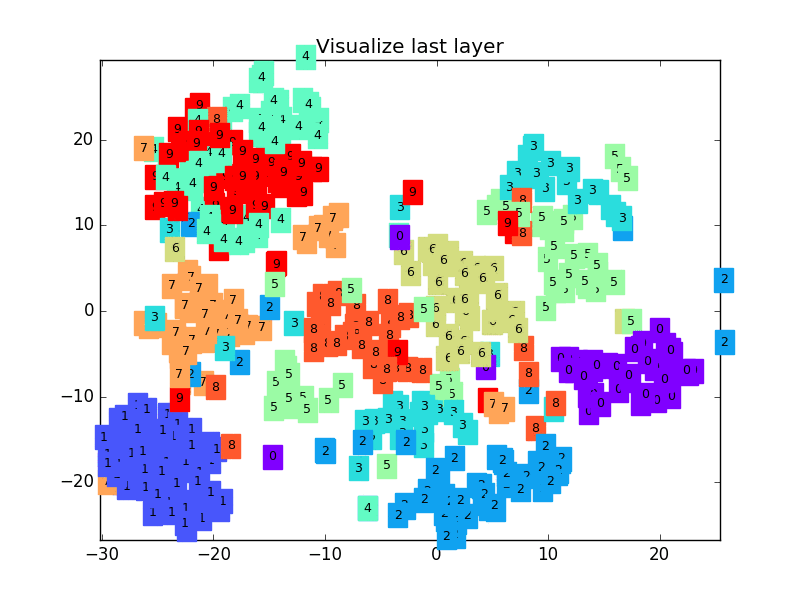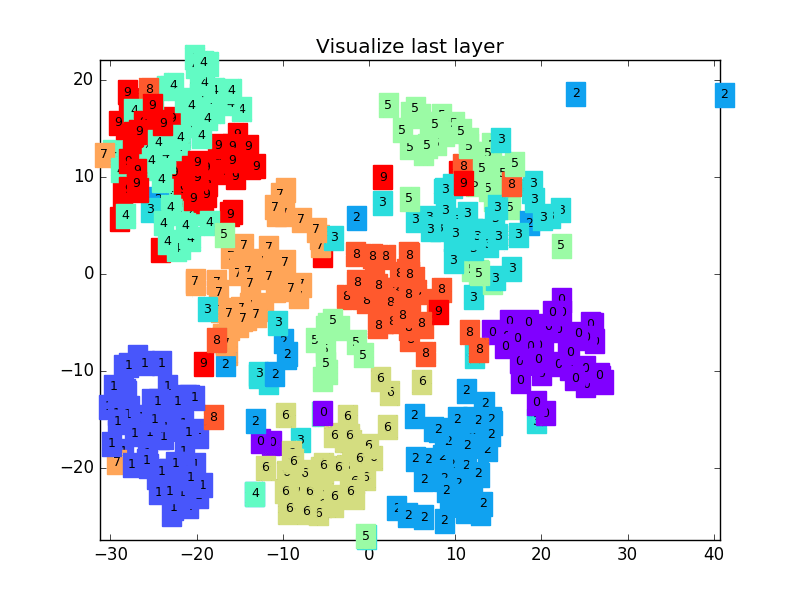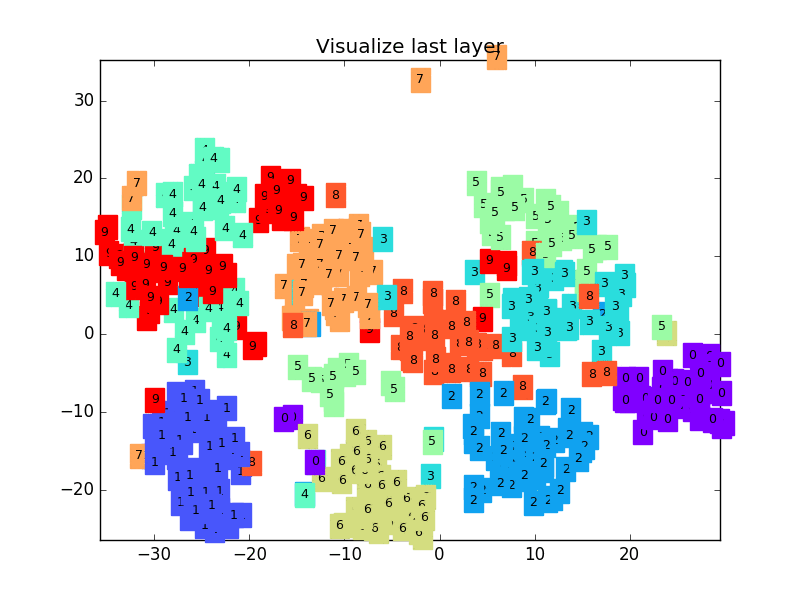 +
+
### [RNN](https://github.com/MorvanZhou/PyTorch-Tutorial/blob/master/tutorial-contents/403_RNN_regressor.py)
diff --git a/tutorial-contents/401_CNN.py b/tutorial-contents/401_CNN.py
index 6602e6a..ed639fb 100644
--- a/tutorial-contents/401_CNN.py
+++ b/tutorial-contents/401_CNN.py
@@ -74,7 +74,7 @@ class CNN(nn.Module):
x = self.conv2(x)
x = x.view(x.size(0), -1) # flatten the output of conv2 to (batch_size, 32 * 7 * 7)
output = self.out(x)
- return output
+ return output, x # return x for visualization
cnn = CNN()
@@ -83,24 +83,53 @@ print(cnn) # net architecture
optimizer = torch.optim.Adam(cnn.parameters(), lr=LR) # optimize all cnn parameters
loss_func = nn.CrossEntropyLoss() # the target label is not one-hotted
+# following function (plot_with_labels) is for visualization, can be ignored if not interested
+from matplotlib import cm
+try:
+ from sklearn.manifold import TSNE
+ HAS_SK = True
+except:
+ HAS_SK = False
+ print('Please install sklearn for layer visualization')
+def plot_with_labels(lowDWeights, labels):
+ plt.cla()
+ X, Y = lowDWeights[:, 0], lowDWeights[:, 1]
+ for x, y, s in zip(X, Y, labels):
+ c = cm.rainbow(int(255 * s / 9))
+ plt.text(x, y, s, backgroundcolor=c, fontsize=9)
+ plt.xlim(X.min(), X.max())
+ plt.ylim(Y.min(), Y.max())
+ plt.title('Visualize last layer')
+ plt.show()
+ plt.pause(0.01)
+
+plt.ion()
+
# training and testing
for epoch in range(EPOCH):
for step, (x, y) in enumerate(train_loader): # gives batch data, normalize x when iterate train_loader
b_x = Variable(x) # batch x
b_y = Variable(y) # batch y
- output = cnn(b_x) # cnn output
+ output = cnn(b_x)[0] # cnn output
loss = loss_func(output, b_y) # cross entropy loss
optimizer.zero_grad() # clear gradients for this training step
loss.backward() # backpropagation, compute gradients
optimizer.step() # apply gradients
if step % 50 == 0:
- test_output = cnn(test_x)
+ test_output, last_layer = cnn(test_x)
pred_y = torch.max(test_output, 1)[1].data.squeeze()
accuracy = sum(pred_y == test_y) / float(test_y.size(0))
print('Epoch: ', epoch, '| train loss: %.4f' % loss.data[0], '| test accuracy: %.2f' % accuracy)
-
+ if HAS_SK:
+ # Visualization of trained flatten layer (T-SNE)
+ tsne = TSNE(perplexity=30, n_components=2, init='pca', n_iter=5000)
+ plot_only = 500
+ low_dim_embs = tsne.fit_transform(last_layer.data.numpy()[:plot_only, :])
+ labels = test_y.numpy()[:plot_only]
+ plot_with_labels(low_dim_embs, labels)
+plt.ioff()
# print 10 predictions from test data
test_output = cnn(test_x[:10])
+
+
### [RNN](https://github.com/MorvanZhou/PyTorch-Tutorial/blob/master/tutorial-contents/403_RNN_regressor.py)
diff --git a/tutorial-contents/401_CNN.py b/tutorial-contents/401_CNN.py
index 6602e6a..ed639fb 100644
--- a/tutorial-contents/401_CNN.py
+++ b/tutorial-contents/401_CNN.py
@@ -74,7 +74,7 @@ class CNN(nn.Module):
x = self.conv2(x)
x = x.view(x.size(0), -1) # flatten the output of conv2 to (batch_size, 32 * 7 * 7)
output = self.out(x)
- return output
+ return output, x # return x for visualization
cnn = CNN()
@@ -83,24 +83,53 @@ print(cnn) # net architecture
optimizer = torch.optim.Adam(cnn.parameters(), lr=LR) # optimize all cnn parameters
loss_func = nn.CrossEntropyLoss() # the target label is not one-hotted
+# following function (plot_with_labels) is for visualization, can be ignored if not interested
+from matplotlib import cm
+try:
+ from sklearn.manifold import TSNE
+ HAS_SK = True
+except:
+ HAS_SK = False
+ print('Please install sklearn for layer visualization')
+def plot_with_labels(lowDWeights, labels):
+ plt.cla()
+ X, Y = lowDWeights[:, 0], lowDWeights[:, 1]
+ for x, y, s in zip(X, Y, labels):
+ c = cm.rainbow(int(255 * s / 9))
+ plt.text(x, y, s, backgroundcolor=c, fontsize=9)
+ plt.xlim(X.min(), X.max())
+ plt.ylim(Y.min(), Y.max())
+ plt.title('Visualize last layer')
+ plt.show()
+ plt.pause(0.01)
+
+plt.ion()
+
# training and testing
for epoch in range(EPOCH):
for step, (x, y) in enumerate(train_loader): # gives batch data, normalize x when iterate train_loader
b_x = Variable(x) # batch x
b_y = Variable(y) # batch y
- output = cnn(b_x) # cnn output
+ output = cnn(b_x)[0] # cnn output
loss = loss_func(output, b_y) # cross entropy loss
optimizer.zero_grad() # clear gradients for this training step
loss.backward() # backpropagation, compute gradients
optimizer.step() # apply gradients
if step % 50 == 0:
- test_output = cnn(test_x)
+ test_output, last_layer = cnn(test_x)
pred_y = torch.max(test_output, 1)[1].data.squeeze()
accuracy = sum(pred_y == test_y) / float(test_y.size(0))
print('Epoch: ', epoch, '| train loss: %.4f' % loss.data[0], '| test accuracy: %.2f' % accuracy)
-
+ if HAS_SK:
+ # Visualization of trained flatten layer (T-SNE)
+ tsne = TSNE(perplexity=30, n_components=2, init='pca', n_iter=5000)
+ plot_only = 500
+ low_dim_embs = tsne.fit_transform(last_layer.data.numpy()[:plot_only, :])
+ labels = test_y.numpy()[:plot_only]
+ plot_with_labels(low_dim_embs, labels)
+plt.ioff()
# print 10 predictions from test data
test_output = cnn(test_x[:10])