diff --git a/README.md b/README.md
index 0b7ec80..eaee0a1 100644
--- a/README.md
+++ b/README.md
@@ -18,9 +18,9 @@ pinned: false
> `pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/`
>
-#  ChatGPT 学术优化
+# GPT 学术优化 (ChatGPT Academic)
-**如果喜欢这个项目,请给它一个Star;如果你发明了更好用的快捷键或函数插件,欢迎发issue或者pull requests**
+**如果喜欢这个项目,请给它一个Star;如果你发明了更好用的快捷键或函数插件,欢迎发pull requests**
If you like this project, please give it a Star. If you've come up with more useful academic shortcuts or functional plugins, feel free to open an issue or pull request. We also have a README in [English|](docs/README_EN.md)[日本語|](docs/README_JP.md)[Русский|](docs/README_RS.md)[Français](docs/README_FR.md) translated by this project itself.
@@ -38,25 +38,25 @@ If you like this project, please give it a Star. If you've come up with more use
--- | ---
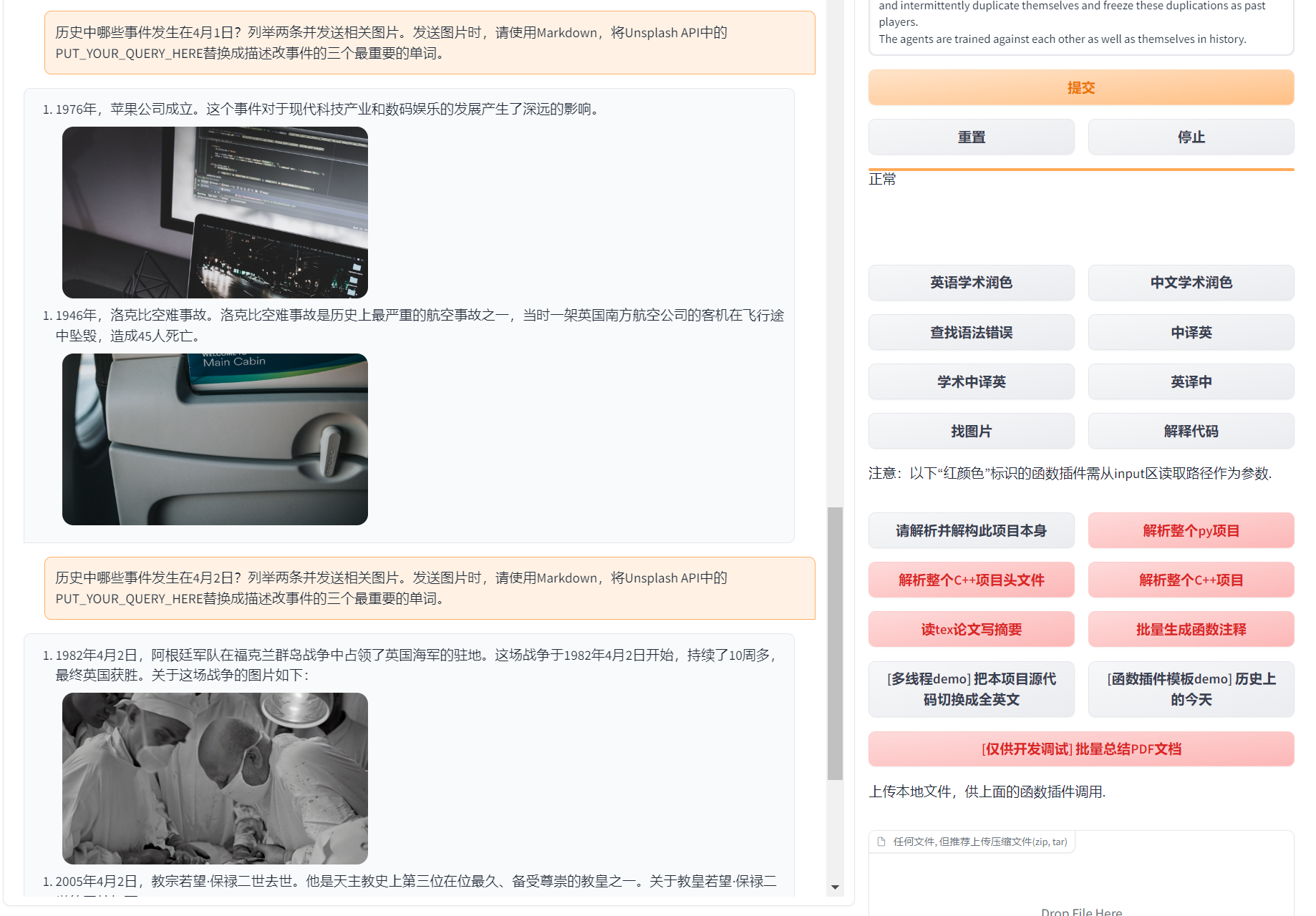
一键润色 | 支持一键润色、一键查找论文语法错误
一键中英互译 | 一键中英互译
-一键代码解释 | 可以正确显示代码、解释代码
+一键代码解释 | 显示代码、解释代码、生成代码、给代码加注释
[自定义快捷键](https://www.bilibili.com/video/BV14s4y1E7jN) | 支持自定义快捷键
-[配置代理服务器](https://www.bilibili.com/video/BV1rc411W7Dr) | 支持代理连接OpenAI/Google等,秒解锁ChatGPT互联网[实时信息聚合](https://www.bilibili.com/video/BV1om4y127ck/)能力
模块化设计 | 支持自定义强大的[函数插件](https://github.com/binary-husky/chatgpt_academic/tree/master/crazy_functions),插件支持[热更新](https://github.com/binary-husky/chatgpt_academic/wiki/%E5%87%BD%E6%95%B0%E6%8F%92%E4%BB%B6%E6%8C%87%E5%8D%97)
[自我程序剖析](https://www.bilibili.com/video/BV1cj411A7VW) | [函数插件] [一键读懂](https://github.com/binary-husky/chatgpt_academic/wiki/chatgpt-academic%E9%A1%B9%E7%9B%AE%E8%87%AA%E8%AF%91%E8%A7%A3%E6%8A%A5%E5%91%8A)本项目的源代码
[程序剖析](https://www.bilibili.com/video/BV1cj411A7VW) | [函数插件] 一键可以剖析其他Python/C/C++/Java/Lua/...项目树
-读论文 | [函数插件] 一键解读latex论文全文并生成摘要
+读论文、[翻译](https://www.bilibili.com/video/BV1KT411x7Wn)论文 | [函数插件] 一键解读latex/pdf论文全文并生成摘要
Latex全文[翻译](https://www.bilibili.com/video/BV1nk4y1Y7Js/)、[润色](https://www.bilibili.com/video/BV1FT411H7c5/) | [函数插件] 一键翻译或润色latex论文
批量注释生成 | [函数插件] 一键批量生成函数注释
-chat分析报告生成 | [函数插件] 运行后自动生成总结汇报
Markdown[中英互译](https://www.bilibili.com/video/BV1yo4y157jV/) | [函数插件] 看到上面5种语言的[README](https://github.com/binary-husky/chatgpt_academic/blob/master/docs/README_EN.md)了吗?
-[arxiv小助手](https://www.bilibili.com/video/BV1LM4y1279X) | [函数插件] 输入arxiv文章url即可一键翻译摘要+下载PDF
+chat分析报告生成 | [函数插件] 运行后自动生成总结汇报
[PDF论文全文翻译功能](https://www.bilibili.com/video/BV1KT411x7Wn) | [函数插件] PDF论文提取题目&摘要+翻译全文(多线程)
+[Arxiv小助手](https://www.bilibili.com/video/BV1LM4y1279X) | [函数插件] 输入arxiv文章url即可一键翻译摘要+下载PDF
[谷歌学术统合小助手](https://www.bilibili.com/video/BV19L411U7ia) | [函数插件] 给定任意谷歌学术搜索页面URL,让gpt帮你[写relatedworks](https://www.bilibili.com/video/BV1GP411U7Az/)
+互联网信息聚合+GPT | [函数插件] 一键[让GPT先从互联网获取信息](https://www.bilibili.com/video/BV1om4y127ck),再回答问题,让信息永不过时
公式/图片/表格显示 | 可以同时显示公式的[tex形式和渲染形式](https://user-images.githubusercontent.com/96192199/230598842-1d7fcddd-815d-40ee-af60-baf488a199df.png),支持公式、代码高亮
多线程函数插件支持 | 支持多线调用chatgpt,一键处理[海量文本](https://www.bilibili.com/video/BV1FT411H7c5/)或程序
启动暗色gradio[主题](https://github.com/binary-husky/chatgpt_academic/issues/173) | 在浏览器url后面添加```/?__dark-theme=true```可以切换dark主题
[多LLM模型](https://www.bilibili.com/video/BV1wT411p7yf)支持,[API2D](https://api2d.com/)接口支持 | 同时被GPT3.5、GPT4和[清华ChatGLM](https://github.com/THUDM/ChatGLM-6B)伺候的感觉一定会很不错吧?
-huggingface免科学上网[在线体验](https://huggingface.co/spaces/qingxu98/gpt-academic) | 登陆huggingface后复制[此空间](https://huggingface.co/spaces/qingxu98/gpt-academic)
+更多LLM模型接入,支持[huggingface部署](https://huggingface.co/spaces/qingxu98/gpt-academic) | 新加入Newbing测试接口(新必应AI)
…… | ……
@@ -93,9 +93,6 @@ huggingface免科学上网[在线体验](https://huggingface.co/spaces/qingxu98/
ChatGPT 学术优化
+# GPT 学术优化 (ChatGPT Academic)
-**如果喜欢这个项目,请给它一个Star;如果你发明了更好用的快捷键或函数插件,欢迎发issue或者pull requests**
+**如果喜欢这个项目,请给它一个Star;如果你发明了更好用的快捷键或函数插件,欢迎发pull requests**
If you like this project, please give it a Star. If you've come up with more useful academic shortcuts or functional plugins, feel free to open an issue or pull request. We also have a README in [English|](docs/README_EN.md)[日本語|](docs/README_JP.md)[Русский|](docs/README_RS.md)[Français](docs/README_FR.md) translated by this project itself.
@@ -38,25 +38,25 @@ If you like this project, please give it a Star. If you've come up with more use
--- | ---
一键润色 | 支持一键润色、一键查找论文语法错误
一键中英互译 | 一键中英互译
-一键代码解释 | 可以正确显示代码、解释代码
+一键代码解释 | 显示代码、解释代码、生成代码、给代码加注释
[自定义快捷键](https://www.bilibili.com/video/BV14s4y1E7jN) | 支持自定义快捷键
-[配置代理服务器](https://www.bilibili.com/video/BV1rc411W7Dr) | 支持代理连接OpenAI/Google等,秒解锁ChatGPT互联网[实时信息聚合](https://www.bilibili.com/video/BV1om4y127ck/)能力
模块化设计 | 支持自定义强大的[函数插件](https://github.com/binary-husky/chatgpt_academic/tree/master/crazy_functions),插件支持[热更新](https://github.com/binary-husky/chatgpt_academic/wiki/%E5%87%BD%E6%95%B0%E6%8F%92%E4%BB%B6%E6%8C%87%E5%8D%97)
[自我程序剖析](https://www.bilibili.com/video/BV1cj411A7VW) | [函数插件] [一键读懂](https://github.com/binary-husky/chatgpt_academic/wiki/chatgpt-academic%E9%A1%B9%E7%9B%AE%E8%87%AA%E8%AF%91%E8%A7%A3%E6%8A%A5%E5%91%8A)本项目的源代码
[程序剖析](https://www.bilibili.com/video/BV1cj411A7VW) | [函数插件] 一键可以剖析其他Python/C/C++/Java/Lua/...项目树
-读论文 | [函数插件] 一键解读latex论文全文并生成摘要
+读论文、[翻译](https://www.bilibili.com/video/BV1KT411x7Wn)论文 | [函数插件] 一键解读latex/pdf论文全文并生成摘要
Latex全文[翻译](https://www.bilibili.com/video/BV1nk4y1Y7Js/)、[润色](https://www.bilibili.com/video/BV1FT411H7c5/) | [函数插件] 一键翻译或润色latex论文
批量注释生成 | [函数插件] 一键批量生成函数注释
-chat分析报告生成 | [函数插件] 运行后自动生成总结汇报
Markdown[中英互译](https://www.bilibili.com/video/BV1yo4y157jV/) | [函数插件] 看到上面5种语言的[README](https://github.com/binary-husky/chatgpt_academic/blob/master/docs/README_EN.md)了吗?
-[arxiv小助手](https://www.bilibili.com/video/BV1LM4y1279X) | [函数插件] 输入arxiv文章url即可一键翻译摘要+下载PDF
+chat分析报告生成 | [函数插件] 运行后自动生成总结汇报
[PDF论文全文翻译功能](https://www.bilibili.com/video/BV1KT411x7Wn) | [函数插件] PDF论文提取题目&摘要+翻译全文(多线程)
+[Arxiv小助手](https://www.bilibili.com/video/BV1LM4y1279X) | [函数插件] 输入arxiv文章url即可一键翻译摘要+下载PDF
[谷歌学术统合小助手](https://www.bilibili.com/video/BV19L411U7ia) | [函数插件] 给定任意谷歌学术搜索页面URL,让gpt帮你[写relatedworks](https://www.bilibili.com/video/BV1GP411U7Az/)
+互联网信息聚合+GPT | [函数插件] 一键[让GPT先从互联网获取信息](https://www.bilibili.com/video/BV1om4y127ck),再回答问题,让信息永不过时
公式/图片/表格显示 | 可以同时显示公式的[tex形式和渲染形式](https://user-images.githubusercontent.com/96192199/230598842-1d7fcddd-815d-40ee-af60-baf488a199df.png),支持公式、代码高亮
多线程函数插件支持 | 支持多线调用chatgpt,一键处理[海量文本](https://www.bilibili.com/video/BV1FT411H7c5/)或程序
启动暗色gradio[主题](https://github.com/binary-husky/chatgpt_academic/issues/173) | 在浏览器url后面添加```/?__dark-theme=true```可以切换dark主题
[多LLM模型](https://www.bilibili.com/video/BV1wT411p7yf)支持,[API2D](https://api2d.com/)接口支持 | 同时被GPT3.5、GPT4和[清华ChatGLM](https://github.com/THUDM/ChatGLM-6B)伺候的感觉一定会很不错吧?
-huggingface免科学上网[在线体验](https://huggingface.co/spaces/qingxu98/gpt-academic) | 登陆huggingface后复制[此空间](https://huggingface.co/spaces/qingxu98/gpt-academic)
+更多LLM模型接入,支持[huggingface部署](https://huggingface.co/spaces/qingxu98/gpt-academic) | 新加入Newbing测试接口(新必应AI)
…… | ……
@@ -93,9 +93,6 @@ huggingface免科学上网[在线体验](https://huggingface.co/spaces/qingxu98/
 -多种大语言模型混合调用[huggingface测试版](https://huggingface.co/spaces/qingxu98/academic-chatgpt-beta)(huggingface版不支持chatglm)
-
-
---
## 安装-方法1:直接运行 (Windows, Linux or MacOS)
@@ -106,20 +103,16 @@ git clone https://github.com/binary-husky/chatgpt_academic.git
cd chatgpt_academic
```
-2. 配置API_KEY和代理设置
+2. 配置API_KEY
+
+在`config.py`中,配置API KEY等[设置](https://github.com/binary-husky/gpt_academic/issues/1) 。
-在`config.py`中,配置 海外Proxy 和 OpenAI API KEY,说明如下
-```
-1. 如果你在国内,需要设置海外代理才能够顺利使用OpenAI API,设置方法请仔细阅读config.py(1.修改其中的USE_PROXY为True; 2.按照说明修改其中的proxies)。
-2. 配置 OpenAI API KEY。支持任意数量的OpenAI的密钥和API2D的密钥共存/负载均衡,多个KEY用英文逗号分隔即可,例如输入 API_KEY="OpenAI密钥1,API2D密钥2,OpenAI密钥3,OpenAI密钥4"
-3. 与代理网络有关的issue(网络超时、代理不起作用)汇总到 https://github.com/binary-husky/chatgpt_academic/issues/1
-```
(P.S. 程序运行时会优先检查是否存在名为`config_private.py`的私密配置文件,并用其中的配置覆盖`config.py`的同名配置。因此,如果您能理解我们的配置读取逻辑,我们强烈建议您在`config.py`旁边创建一个名为`config_private.py`的新配置文件,并把`config.py`中的配置转移(复制)到`config_private.py`中。`config_private.py`不受git管控,可以让您的隐私信息更加安全。)
3. 安装依赖
```sh
-# (选择I: 如熟悉python)推荐
+# (选择I: 如熟悉python)(python版本3.9以上,越新越好)
python -m pip install -r requirements.txt
# 备注:使用官方pip源或者阿里pip源,其他pip源(如一些大学的pip)有可能出问题,临时换源方法:python -m pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/
@@ -141,14 +134,8 @@ python main.py
5. 测试函数插件
```
-- 测试Python项目分析
- (选择1)input区域 输入 `./crazy_functions/test_project/python/dqn` , 然后点击 "解析整个Python项目"
- (选择2)展开文件上传区,将python文件/包含python文件的压缩包拖拽进去,在出现反馈提示后, 然后点击 "解析整个Python项目"
-- 测试自我代码解读(本项目自译解)
- 点击 "[多线程Demo] 解析此项目本身(源码自译解)"
- 测试函数插件模板函数(要求gpt回答历史上的今天发生了什么),您可以根据此函数为模板,实现更复杂的功能
点击 "[函数插件模板Demo] 历史上的今天"
-- 函数插件区下拉菜单中有更多功能可供选择
```
## 安装-方法2:使用Docker
@@ -159,7 +146,7 @@ python main.py
# 下载项目
git clone https://github.com/binary-husky/chatgpt_academic.git
cd chatgpt_academic
-# 配置 “海外Proxy”, “API_KEY” 以及 “WEB_PORT” (例如50923) 等
+# 配置 “Proxy”, “API_KEY” 以及 “WEB_PORT” (例如50923) 等
用任意文本编辑器编辑 config.py
# 安装
docker build -t gpt-academic .
@@ -182,26 +169,20 @@ docker run --rm -it --net=host --gpus=all gpt-academic
docker run --rm -it --net=host --gpus=all gpt-academic bash
```
+## 安装-方法3:其他部署姿势
-## 安装-方法3:其他部署方式(需要云服务器知识与经验)
+1. 如何使用反代URL/AzureAPI
+按照`config.py`中的说明配置API_URL_REDIRECT即可。
-1. 远程云服务器部署
+2. 远程云服务器部署(需要云服务器知识与经验)
请访问[部署wiki-1](https://github.com/binary-husky/chatgpt_academic/wiki/%E4%BA%91%E6%9C%8D%E5%8A%A1%E5%99%A8%E8%BF%9C%E7%A8%8B%E9%83%A8%E7%BD%B2%E6%8C%87%E5%8D%97)
-2. 使用WSL2(Windows Subsystem for Linux 子系统)
+3. 使用WSL2(Windows Subsystem for Linux 子系统)
请访问[部署wiki-2](https://github.com/binary-husky/chatgpt_academic/wiki/%E4%BD%BF%E7%94%A8WSL2%EF%BC%88Windows-Subsystem-for-Linux-%E5%AD%90%E7%B3%BB%E7%BB%9F%EF%BC%89%E9%83%A8%E7%BD%B2)
-3. 如何在二级网址(如`http://localhost/subpath`)下运行
+4. 如何在二级网址(如`http://localhost/subpath`)下运行
请访问[FastAPI运行说明](docs/WithFastapi.md)
-## 安装-代理配置
-1. 常规方法
-[配置代理](https://github.com/binary-husky/chatgpt_academic/issues/1)
-
-2. 纯新手教程
-[纯新手教程](https://github.com/binary-husky/chatgpt_academic/wiki/%E4%BB%A3%E7%90%86%E8%BD%AF%E4%BB%B6%E9%97%AE%E9%A2%98%E7%9A%84%E6%96%B0%E6%89%8B%E8%A7%A3%E5%86%B3%E6%96%B9%E6%B3%95%EF%BC%88%E6%96%B9%E6%B3%95%E5%8F%AA%E9%80%82%E7%94%A8%E4%BA%8E%E6%96%B0%E6%89%8B%EF%BC%89)
-
-
---
## 自定义新的便捷按钮 / 自定义函数插件
@@ -228,74 +209,48 @@ docker run --rm -it --net=host --gpus=all gpt-academic bash
本项目的插件编写、调试难度很低,只要您具备一定的python基础知识,就可以仿照我们提供的模板实现自己的插件功能。
详情请参考[函数插件指南](https://github.com/binary-husky/chatgpt_academic/wiki/%E5%87%BD%E6%95%B0%E6%8F%92%E4%BB%B6%E6%8C%87%E5%8D%97)。
-
---
+## 其他功能说明
-## 部分功能展示
-
-1. 图片显示:
-
+1. 对话保存功能。在函数插件区调用 `保存当前的对话` 即可将当前对话保存为可读+可复原的html文件,如图:
-多种大语言模型混合调用[huggingface测试版](https://huggingface.co/spaces/qingxu98/academic-chatgpt-beta)(huggingface版不支持chatglm)
-
-
---
## 安装-方法1:直接运行 (Windows, Linux or MacOS)
@@ -106,20 +103,16 @@ git clone https://github.com/binary-husky/chatgpt_academic.git
cd chatgpt_academic
```
-2. 配置API_KEY和代理设置
+2. 配置API_KEY
+
+在`config.py`中,配置API KEY等[设置](https://github.com/binary-husky/gpt_academic/issues/1) 。
-在`config.py`中,配置 海外Proxy 和 OpenAI API KEY,说明如下
-```
-1. 如果你在国内,需要设置海外代理才能够顺利使用OpenAI API,设置方法请仔细阅读config.py(1.修改其中的USE_PROXY为True; 2.按照说明修改其中的proxies)。
-2. 配置 OpenAI API KEY。支持任意数量的OpenAI的密钥和API2D的密钥共存/负载均衡,多个KEY用英文逗号分隔即可,例如输入 API_KEY="OpenAI密钥1,API2D密钥2,OpenAI密钥3,OpenAI密钥4"
-3. 与代理网络有关的issue(网络超时、代理不起作用)汇总到 https://github.com/binary-husky/chatgpt_academic/issues/1
-```
(P.S. 程序运行时会优先检查是否存在名为`config_private.py`的私密配置文件,并用其中的配置覆盖`config.py`的同名配置。因此,如果您能理解我们的配置读取逻辑,我们强烈建议您在`config.py`旁边创建一个名为`config_private.py`的新配置文件,并把`config.py`中的配置转移(复制)到`config_private.py`中。`config_private.py`不受git管控,可以让您的隐私信息更加安全。)
3. 安装依赖
```sh
-# (选择I: 如熟悉python)推荐
+# (选择I: 如熟悉python)(python版本3.9以上,越新越好)
python -m pip install -r requirements.txt
# 备注:使用官方pip源或者阿里pip源,其他pip源(如一些大学的pip)有可能出问题,临时换源方法:python -m pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/
@@ -141,14 +134,8 @@ python main.py
5. 测试函数插件
```
-- 测试Python项目分析
- (选择1)input区域 输入 `./crazy_functions/test_project/python/dqn` , 然后点击 "解析整个Python项目"
- (选择2)展开文件上传区,将python文件/包含python文件的压缩包拖拽进去,在出现反馈提示后, 然后点击 "解析整个Python项目"
-- 测试自我代码解读(本项目自译解)
- 点击 "[多线程Demo] 解析此项目本身(源码自译解)"
- 测试函数插件模板函数(要求gpt回答历史上的今天发生了什么),您可以根据此函数为模板,实现更复杂的功能
点击 "[函数插件模板Demo] 历史上的今天"
-- 函数插件区下拉菜单中有更多功能可供选择
```
## 安装-方法2:使用Docker
@@ -159,7 +146,7 @@ python main.py
# 下载项目
git clone https://github.com/binary-husky/chatgpt_academic.git
cd chatgpt_academic
-# 配置 “海外Proxy”, “API_KEY” 以及 “WEB_PORT” (例如50923) 等
+# 配置 “Proxy”, “API_KEY” 以及 “WEB_PORT” (例如50923) 等
用任意文本编辑器编辑 config.py
# 安装
docker build -t gpt-academic .
@@ -182,26 +169,20 @@ docker run --rm -it --net=host --gpus=all gpt-academic
docker run --rm -it --net=host --gpus=all gpt-academic bash
```
+## 安装-方法3:其他部署姿势
-## 安装-方法3:其他部署方式(需要云服务器知识与经验)
+1. 如何使用反代URL/AzureAPI
+按照`config.py`中的说明配置API_URL_REDIRECT即可。
-1. 远程云服务器部署
+2. 远程云服务器部署(需要云服务器知识与经验)
请访问[部署wiki-1](https://github.com/binary-husky/chatgpt_academic/wiki/%E4%BA%91%E6%9C%8D%E5%8A%A1%E5%99%A8%E8%BF%9C%E7%A8%8B%E9%83%A8%E7%BD%B2%E6%8C%87%E5%8D%97)
-2. 使用WSL2(Windows Subsystem for Linux 子系统)
+3. 使用WSL2(Windows Subsystem for Linux 子系统)
请访问[部署wiki-2](https://github.com/binary-husky/chatgpt_academic/wiki/%E4%BD%BF%E7%94%A8WSL2%EF%BC%88Windows-Subsystem-for-Linux-%E5%AD%90%E7%B3%BB%E7%BB%9F%EF%BC%89%E9%83%A8%E7%BD%B2)
-3. 如何在二级网址(如`http://localhost/subpath`)下运行
+4. 如何在二级网址(如`http://localhost/subpath`)下运行
请访问[FastAPI运行说明](docs/WithFastapi.md)
-## 安装-代理配置
-1. 常规方法
-[配置代理](https://github.com/binary-husky/chatgpt_academic/issues/1)
-
-2. 纯新手教程
-[纯新手教程](https://github.com/binary-husky/chatgpt_academic/wiki/%E4%BB%A3%E7%90%86%E8%BD%AF%E4%BB%B6%E9%97%AE%E9%A2%98%E7%9A%84%E6%96%B0%E6%89%8B%E8%A7%A3%E5%86%B3%E6%96%B9%E6%B3%95%EF%BC%88%E6%96%B9%E6%B3%95%E5%8F%AA%E9%80%82%E7%94%A8%E4%BA%8E%E6%96%B0%E6%89%8B%EF%BC%89)
-
-
---
## 自定义新的便捷按钮 / 自定义函数插件
@@ -228,74 +209,48 @@ docker run --rm -it --net=host --gpus=all gpt-academic bash
本项目的插件编写、调试难度很低,只要您具备一定的python基础知识,就可以仿照我们提供的模板实现自己的插件功能。
详情请参考[函数插件指南](https://github.com/binary-husky/chatgpt_academic/wiki/%E5%87%BD%E6%95%B0%E6%8F%92%E4%BB%B6%E6%8C%87%E5%8D%97)。
-
---
+## 其他功能说明
-## 部分功能展示
-
-1. 图片显示:
-
+1. 对话保存功能。在函数插件区调用 `保存当前的对话` 即可将当前对话保存为可读+可复原的html文件,如图:
-
+

-

-
-

-
-

-
-

-
-

-
-
+
+
+
')
f.write('
\n\n')
-
+ f.write('
\n\n raw chat context:\n')
+ f.write('')
+ for h in history:
+ f.write("\n>>>" + h)
+ f.write('')
res = '对话历史写入:' + os.path.abspath(f'./gpt_log/{file_name}')
print(res)
return res
+def gen_file_preview(file_name):
+ try:
+ with open(file_name, 'r', encoding='utf8') as f:
+ file_content = f.read()
+ # pattern to match the text between and
+ pattern = re.compile(r'.*?', flags=re.DOTALL)
+ file_content = re.sub(pattern, '', file_content)
+ html, history = file_content.split('
\n\n raw chat context:\n')
+ history = history.strip('')
+ history = history.strip('')
+ history = history.split("\n>>>")
+ return list(filter(lambda x:x!="", history))[0][:100]
+ except:
+ return ""
+
+def read_file_to_chat(chatbot, history, file_name):
+ with open(file_name, 'r', encoding='utf8') as f:
+ file_content = f.read()
+ # pattern to match the text between and
+ pattern = re.compile(r'.*?', flags=re.DOTALL)
+ file_content = re.sub(pattern, '', file_content)
+ html, history = file_content.split('
\n\n raw chat context:\n')
+ history = history.strip('')
+ history = history.strip('')
+ history = history.split("\n>>>")
+ history = list(filter(lambda x:x!="", history))
+ html = html.split('
\n\n')
+ html = list(filter(lambda x:x!="", html))
+ chatbot.clear()
+ for i, h in enumerate(html):
+ i_say, gpt_say = h.split('
')
+ chatbot.append([i_say, gpt_say])
+ chatbot.append([f"存档文件详情?", f"[Local Message] 载入对话{len(html)}条,上下文{len(history)}条。"])
+ return chatbot, history
+
@CatchException
def 对话历史存档(txt, llm_kwargs, plugin_kwargs, chatbot, history, system_prompt, web_port):
"""
@@ -37,6 +80,64 @@ def 对话历史存档(txt, llm_kwargs, plugin_kwargs, chatbot, history, system_
web_port 当前软件运行的端口号
"""
- chatbot.append(("保存当前对话", f"[Local Message] {write_chat_to_file(chatbot)}"))
+ chatbot.append(("保存当前对话",
+ f"[Local Message] {write_chat_to_file(chatbot, history)},您可以调用“载入对话历史存档”还原当下的对话。\n警告!被保存的对话历史可以被使用该系统的任何人查阅。"))
yield from update_ui(chatbot=chatbot, history=history) # 刷新界面 # 由于请求gpt需要一段时间,我们先及时地做一次界面更新
+def hide_cwd(str):
+ import os
+ current_path = os.getcwd()
+ replace_path = "."
+ return str.replace(current_path, replace_path)
+
+@CatchException
+def 载入对话历史存档(txt, llm_kwargs, plugin_kwargs, chatbot, history, system_prompt, web_port):
+ """
+ txt 输入栏用户输入的文本,例如需要翻译的一段话,再例如一个包含了待处理文件的路径
+ llm_kwargs gpt模型参数,如温度和top_p等,一般原样传递下去就行
+ plugin_kwargs 插件模型的参数,暂时没有用武之地
+ chatbot 聊天显示框的句柄,用于显示给用户
+ history 聊天历史,前情提要
+ system_prompt 给gpt的静默提醒
+ web_port 当前软件运行的端口号
+ """
+ from .crazy_utils import get_files_from_everything
+ success, file_manifest, _ = get_files_from_everything(txt, type='.html')
+
+ if not success:
+ if txt == "": txt = '空空如也的输入栏'
+ import glob
+ local_history = "
".join(["`"+hide_cwd(f)+f" ({gen_file_preview(f)})"+"`" for f in glob.glob(f'gpt_log/**/chatGPT对话历史*.html', recursive=True)])
+ chatbot.append([f"正在查找对话历史文件(html格式): {txt}", f"找不到任何html文件: {txt}。但本地存储了以下历史文件,您可以将任意一个文件路径粘贴到输入区,然后重试:
{local_history}"])
+ yield from update_ui(chatbot=chatbot, history=history) # 刷新界面
+ return
+
+ try:
+ chatbot, history = read_file_to_chat(chatbot, history, file_manifest[0])
+ yield from update_ui(chatbot=chatbot, history=history) # 刷新界面
+ except:
+ chatbot.append([f"载入对话历史文件", f"对话历史文件损坏!"])
+ yield from update_ui(chatbot=chatbot, history=history) # 刷新界面
+ return
+
+@CatchException
+def 删除所有本地对话历史记录(txt, llm_kwargs, plugin_kwargs, chatbot, history, system_prompt, web_port):
+ """
+ txt 输入栏用户输入的文本,例如需要翻译的一段话,再例如一个包含了待处理文件的路径
+ llm_kwargs gpt模型参数,如温度和top_p等,一般原样传递下去就行
+ plugin_kwargs 插件模型的参数,暂时没有用武之地
+ chatbot 聊天显示框的句柄,用于显示给用户
+ history 聊天历史,前情提要
+ system_prompt 给gpt的静默提醒
+ web_port 当前软件运行的端口号
+ """
+
+ import glob, os
+ local_history = "
".join(["`"+hide_cwd(f)+"`" for f in glob.glob(f'gpt_log/**/chatGPT对话历史*.html', recursive=True)])
+ for f in glob.glob(f'gpt_log/**/chatGPT对话历史*.html', recursive=True):
+ os.remove(f)
+ chatbot.append([f"删除所有历史对话文件", f"已删除
{local_history}"])
+ yield from update_ui(chatbot=chatbot, history=history) # 刷新界面
+ return
+
+
diff --git a/crazy_functions/批量Markdown翻译.py b/crazy_functions/批量Markdown翻译.py
index ee6a1a4..26f42ca 100644
--- a/crazy_functions/批量Markdown翻译.py
+++ b/crazy_functions/批量Markdown翻译.py
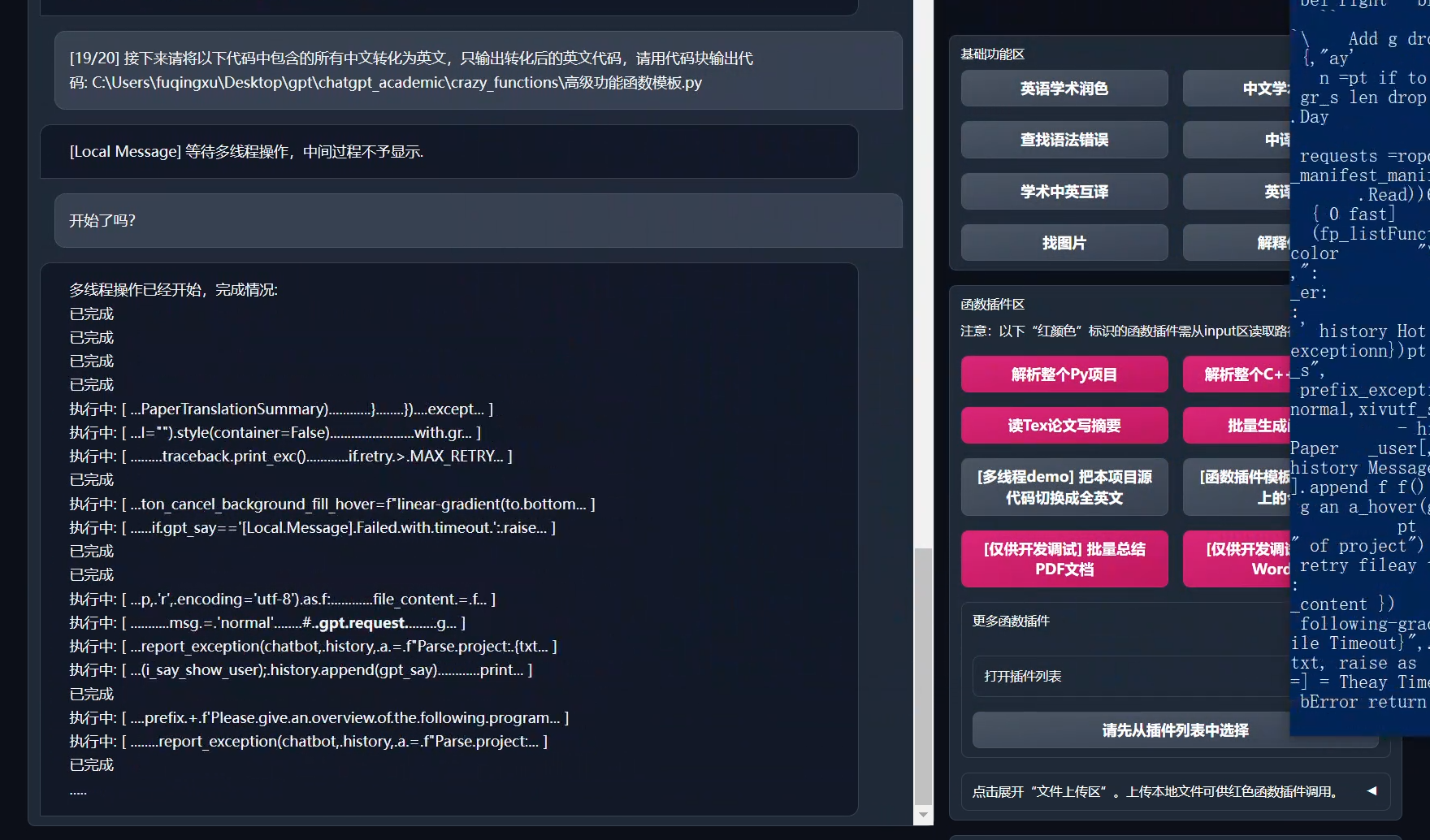
@@ -84,7 +84,33 @@ def 多文件翻译(file_manifest, project_folder, llm_kwargs, plugin_kwargs, ch
yield from update_ui(chatbot=chatbot, history=history) # 刷新界面
+def get_files_from_everything(txt):
+ import glob, os
+ success = True
+ if txt.startswith('http'):
+ # 网络的远程文件
+ txt = txt.replace("https://github.com/", "https://raw.githubusercontent.com/")
+ txt = txt.replace("/blob/", "/")
+ import requests
+ from toolbox import get_conf
+ proxies, = get_conf('proxies')
+ r = requests.get(txt, proxies=proxies)
+ with open('./gpt_log/temp.md', 'wb+') as f: f.write(r.content)
+ project_folder = './gpt_log/'
+ file_manifest = ['./gpt_log/temp.md']
+ elif txt.endswith('.md'):
+ # 直接给定文件
+ file_manifest = [txt]
+ project_folder = os.path.dirname(txt)
+ elif os.path.exists(txt):
+ # 本地路径,递归搜索
+ project_folder = txt
+ file_manifest = [f for f in glob.glob(f'{project_folder}/**/*.md', recursive=True)]
+ else:
+ success = False
+
+ return success, file_manifest, project_folder
@CatchException
@@ -98,6 +124,7 @@ def Markdown英译中(txt, llm_kwargs, plugin_kwargs, chatbot, history, system_p
# 尝试导入依赖,如果缺少依赖,则给出安装建议
try:
import tiktoken
+ import glob, os
except:
report_execption(chatbot, history,
a=f"解析项目: {txt}",
@@ -105,19 +132,21 @@ def Markdown英译中(txt, llm_kwargs, plugin_kwargs, chatbot, history, system_p
yield from update_ui(chatbot=chatbot, history=history) # 刷新界面
return
history = [] # 清空历史,以免输入溢出
- import glob, os
- if os.path.exists(txt):
- project_folder = txt
- else:
+
+ success, file_manifest, project_folder = get_files_from_everything(txt)
+
+ if not success:
+ # 什么都没有
if txt == "": txt = '空空如也的输入栏'
report_execption(chatbot, history, a = f"解析项目: {txt}", b = f"找不到本地项目或无权访问: {txt}")
yield from update_ui(chatbot=chatbot, history=history) # 刷新界面
return
- file_manifest = [f for f in glob.glob(f'{project_folder}/**/*.md', recursive=True)]
+
if len(file_manifest) == 0:
report_execption(chatbot, history, a = f"解析项目: {txt}", b = f"找不到任何.md文件: {txt}")
yield from update_ui(chatbot=chatbot, history=history) # 刷新界面
return
+
yield from 多文件翻译(file_manifest, project_folder, llm_kwargs, plugin_kwargs, chatbot, history, system_prompt, language='en->zh')
@@ -135,6 +164,7 @@ def Markdown中译英(txt, llm_kwargs, plugin_kwargs, chatbot, history, system_p
# 尝试导入依赖,如果缺少依赖,则给出安装建议
try:
import tiktoken
+ import glob, os
except:
report_execption(chatbot, history,
a=f"解析项目: {txt}",
@@ -142,18 +172,13 @@ def Markdown中译英(txt, llm_kwargs, plugin_kwargs, chatbot, history, system_p
yield from update_ui(chatbot=chatbot, history=history) # 刷新界面
return
history = [] # 清空历史,以免输入溢出
- import glob, os
- if os.path.exists(txt):
- project_folder = txt
- else:
+ success, file_manifest, project_folder = get_files_from_everything(txt)
+ if not success:
+ # 什么都没有
if txt == "": txt = '空空如也的输入栏'
report_execption(chatbot, history, a = f"解析项目: {txt}", b = f"找不到本地项目或无权访问: {txt}")
yield from update_ui(chatbot=chatbot, history=history) # 刷新界面
return
- if txt.endswith('.md'):
- file_manifest = [txt]
- else:
- file_manifest = [f for f in glob.glob(f'{project_folder}/**/*.md', recursive=True)]
if len(file_manifest) == 0:
report_execption(chatbot, history, a = f"解析项目: {txt}", b = f"找不到任何.md文件: {txt}")
yield from update_ui(chatbot=chatbot, history=history) # 刷新界面
diff --git a/crazy_functions/解析项目源代码.py b/crazy_functions/解析项目源代码.py
index bfa473a..49f41b1 100644
--- a/crazy_functions/解析项目源代码.py
+++ b/crazy_functions/解析项目源代码.py
@@ -1,5 +1,6 @@
from toolbox import update_ui
from toolbox import CatchException, report_execption, write_results_to_file
+from .crazy_utils import input_clipping
def 解析源代码新(file_manifest, project_folder, llm_kwargs, plugin_kwargs, chatbot, history, system_prompt):
import os, copy
@@ -61,13 +62,15 @@ def 解析源代码新(file_manifest, project_folder, llm_kwargs, plugin_kwargs,
previous_iteration_files.extend([os.path.relpath(fp, project_folder) for index, fp in enumerate(this_iteration_file_manifest)])
previous_iteration_files_string = ', '.join(previous_iteration_files)
current_iteration_focus = ', '.join([os.path.relpath(fp, project_folder) for index, fp in enumerate(this_iteration_file_manifest)])
- i_say = f'根据以上分析,对程序的整体功能和构架重新做出概括。然后用一张markdown表格整理每个文件的功能(包括{previous_iteration_files_string})。'
+ i_say = f'用一张Markdown表格简要描述以下文件的功能:{previous_iteration_files_string}。根据以上分析,用一句话概括程序的整体功能。'
inputs_show_user = f'根据以上分析,对程序的整体功能和构架重新做出概括,由于输入长度限制,可能需要分组处理,本组文件为 {current_iteration_focus} + 已经汇总的文件组。'
this_iteration_history = copy.deepcopy(this_iteration_gpt_response_collection)
this_iteration_history.append(last_iteration_result)
+ # 裁剪input
+ inputs, this_iteration_history_feed = input_clipping(inputs=i_say, history=this_iteration_history, max_token_limit=2560)
result = yield from request_gpt_model_in_new_thread_with_ui_alive(
- inputs=i_say, inputs_show_user=inputs_show_user, llm_kwargs=llm_kwargs, chatbot=chatbot,
- history=this_iteration_history, # 迭代之前的分析
+ inputs=inputs, inputs_show_user=inputs_show_user, llm_kwargs=llm_kwargs, chatbot=chatbot,
+ history=this_iteration_history_feed, # 迭代之前的分析
sys_prompt="你是一个程序架构分析师,正在分析一个项目的源代码。")
report_part_2.extend([i_say, result])
last_iteration_result = result
diff --git a/docs/Dockerfile+ChatGLM b/docs/Dockerfile+ChatGLM
index dafcee7..9e6db27 100644
--- a/docs/Dockerfile+ChatGLM
+++ b/docs/Dockerfile+ChatGLM
@@ -1,6 +1,6 @@
# How to build | 如何构建: docker build -t gpt-academic --network=host -f Dockerfile+ChatGLM .
-# How to run | 如何运行 (1) 直接运行(选择0号GPU): docker run --rm -it --net=host --gpus="0" gpt-academic
-# How to run | 如何运行 (2) 我想运行之前进容器做一些调整: docker run --rm -it --net=host --gpus="0" gpt-academic bash
+# How to run | (1) 我想直接一键运行(选择0号GPU): docker run --rm -it --net=host --gpus \"device=0\" gpt-academic
+# How to run | (2) 我想运行之前进容器做一些调整(选择1号GPU): docker run --rm -it --net=host --gpus \"device=1\" gpt-academic bash
# 从NVIDIA源,从而支持显卡运损(检查宿主的nvidia-smi中的cuda版本必须>=11.3)
FROM nvidia/cuda:11.3.1-runtime-ubuntu20.04
@@ -14,6 +14,7 @@ RUN apt-get install -y git python python3 python-dev python3-dev --fix-missing
RUN $useProxyNetwork curl cip.cc
RUN sed -i '$ d' /etc/proxychains.conf
RUN sed -i '$ d' /etc/proxychains.conf
+# 在这里填写主机的代理协议(用于从github拉取代码)
RUN echo "socks5 127.0.0.1 10880" >> /etc/proxychains.conf
ARG useProxyNetwork=proxychains
# # comment out above if you do not need proxy network | 如果不需要翻墙 - 从此行向上删除
@@ -21,14 +22,15 @@ ARG useProxyNetwork=proxychains
# use python3 as the system default python
RUN curl -sS https://bootstrap.pypa.io/get-pip.py | python3.8
-
+# 下载pytorch
+RUN $useProxyNetwork python3 -m pip install torch --extra-index-url https://download.pytorch.org/whl/cu113
# 下载分支
WORKDIR /gpt
RUN $useProxyNetwork git clone https://github.com/binary-husky/chatgpt_academic.git
WORKDIR /gpt/chatgpt_academic
RUN $useProxyNetwork python3 -m pip install -r requirements.txt
RUN $useProxyNetwork python3 -m pip install -r request_llm/requirements_chatglm.txt
-RUN $useProxyNetwork python3 -m pip install torch --extra-index-url https://download.pytorch.org/whl/cu113
+RUN $useProxyNetwork python3 -m pip install -r request_llm/requirements_newbing.txt
# 预热CHATGLM参数(非必要 可选步骤)
RUN echo ' \n\
@@ -48,6 +50,7 @@ RUN python3 -c 'from check_proxy import warm_up_modules; warm_up_modules()'
# 可同时填写多个API-KEY,支持openai的key和api2d的key共存,用英文逗号分割,例如API_KEY = "sk-openaikey1,fkxxxx-api2dkey2,........"
# LLM_MODEL 是选择初始的模型
# LOCAL_MODEL_DEVICE 是选择chatglm等本地模型运行的设备,可选 cpu 和 cuda
+# [说明: 以下内容与`config.py`一一对应,请查阅config.py来完成一下配置的填写]
RUN echo ' \n\
API_KEY = "sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx,fkxxxxxx-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx" \n\
USE_PROXY = True \n\
diff --git a/docs/test_markdown_format.py b/docs/test_markdown_format.py
new file mode 100644
index 0000000..896f6f1
--- /dev/null
+++ b/docs/test_markdown_format.py
@@ -0,0 +1,130 @@
+sample = """
+[1]: https://baike.baidu.com/item/%E8%B4%A8%E8%83%BD%E6%96%B9%E7%A8%8B/1884527 "质能方程(质能方程式)_百度百科"
+[2]: https://www.zhihu.com/question/348249281 "如何理解质能方程 E=mc²? - 知乎"
+[3]: https://zhuanlan.zhihu.com/p/32597385 "质能方程的推导与理解 - 知乎 - 知乎专栏"
+
+你好,这是必应。质能方程是描述质量与能量之间的当量关系的方程[^1^][1]。用tex格式,质能方程可以写成$$E=mc^2$$,其中$E$是能量,$m$是质量,$c$是光速[^2^][2] [^3^][3]。
+"""
+import re
+
+def preprocess_newbing_out(s):
+ pattern = r'\^(\d+)\^' # 匹配^数字^
+ pattern2 = r'\[(\d+)\]' # 匹配^数字^
+ sub = lambda m: '\['+m.group(1)+'\]' # 将匹配到的数字作为替换值
+ result = re.sub(pattern, sub, s) # 替换操作
+ if '[1]' in result:
+ result += '
' + "
".join([re.sub(pattern2, sub, r) for r in result.split('\n') if r.startswith('[')]) + ''
+ return result
+
+
+def close_up_code_segment_during_stream(gpt_reply):
+ """
+ 在gpt输出代码的中途(输出了前面的```,但还没输出完后面的```),补上后面的```
+
+ Args:
+ gpt_reply (str): GPT模型返回的回复字符串。
+
+ Returns:
+ str: 返回一个新的字符串,将输出代码片段的“后面的```”补上。
+
+ """
+ if '```' not in gpt_reply:
+ return gpt_reply
+ if gpt_reply.endswith('```'):
+ return gpt_reply
+
+ # 排除了以上两个情况,我们
+ segments = gpt_reply.split('```')
+ n_mark = len(segments) - 1
+ if n_mark % 2 == 1:
+ # print('输出代码片段中!')
+ return gpt_reply+'\n```'
+ else:
+ return gpt_reply
+
+import markdown
+from latex2mathml.converter import convert as tex2mathml
+from functools import wraps, lru_cache
+def markdown_convertion(txt):
+ """
+ 将Markdown格式的文本转换为HTML格式。如果包含数学公式,则先将公式转换为HTML格式。
+ """
+ pre = ''
+ suf = '
'
+ if txt.startswith(pre) and txt.endswith(suf):
+ # print('警告,输入了已经经过转化的字符串,二次转化可能出问题')
+ return txt # 已经被转化过,不需要再次转化
+
+ markdown_extension_configs = {
+ 'mdx_math': {
+ 'enable_dollar_delimiter': True,
+ 'use_gitlab_delimiters': False,
+ },
+ }
+ find_equation_pattern = r'\n', '')
+ return content
+
+
+ if ('$' in txt) and ('```' not in txt): # 有$标识的公式符号,且没有代码段```的标识
+ # convert everything to html format
+ split = markdown.markdown(text='---')
+ convert_stage_1 = markdown.markdown(text=txt, extensions=['mdx_math', 'fenced_code', 'tables', 'sane_lists'], extension_configs=markdown_extension_configs)
+ convert_stage_1 = markdown_bug_hunt(convert_stage_1)
+ # re.DOTALL: Make the '.' special character match any character at all, including a newline; without this flag, '.' will match anything except a newline. Corresponds to the inline flag (?s).
+ # 1. convert to easy-to-copy tex (do not render math)
+ convert_stage_2_1, n = re.subn(find_equation_pattern, replace_math_no_render, convert_stage_1, flags=re.DOTALL)
+ # 2. convert to rendered equation
+ convert_stage_2_2, n = re.subn(find_equation_pattern, replace_math_render, convert_stage_1, flags=re.DOTALL)
+ # cat them together
+ return pre + convert_stage_2_1 + f'{split}' + convert_stage_2_2 + suf
+ else:
+ return pre + markdown.markdown(txt, extensions=['fenced_code', 'codehilite', 'tables', 'sane_lists']) + suf
+
+
+sample = preprocess_newbing_out(sample)
+sample = close_up_code_segment_during_stream(sample)
+sample = markdown_convertion(sample)
+with open('tmp.html', 'w', encoding='utf8') as f:
+ f.write("""
+
+
+ My Website
+
+
+
+ """)
+ f.write(sample)
diff --git a/main.py b/main.py
index d100d4f..dfd232c 100644
--- a/main.py
+++ b/main.py
@@ -174,9 +174,6 @@ def main():
yield from ArgsGeneralWrapper(crazy_fns[k]["Function"])(*args, **kwargs)
click_handle = switchy_bt.click(route,[switchy_bt, *input_combo, gr.State(PORT)], output_combo)
click_handle.then(on_report_generated, [file_upload, chatbot], [file_upload, chatbot])
- # def expand_file_area(file_upload, area_file_up):
- # if len(file_upload)>0: return {area_file_up: gr.update(open=True)}
- # click_handle.then(expand_file_area, [file_upload, area_file_up], [area_file_up])
cancel_handles.append(click_handle)
# 终止按钮的回调函数注册
stopBtn.click(fn=None, inputs=None, outputs=None, cancels=cancel_handles)
@@ -190,7 +187,9 @@ def main():
print(f"\t(暗色主题): http://localhost:{PORT}/?__dark-theme=true")
def open():
time.sleep(2) # 打开浏览器
- webbrowser.open_new_tab(f"http://localhost:{PORT}/?__dark-theme=true")
+ DARK_MODE, = get_conf('DARK_MODE')
+ if DARK_MODE: webbrowser.open_new_tab(f"http://localhost:{PORT}/?__dark-theme=true")
+ else: webbrowser.open_new_tab(f"http://localhost:{PORT}")
threading.Thread(target=open, name="open-browser", daemon=True).start()
threading.Thread(target=auto_update, name="self-upgrade", daemon=True).start()
threading.Thread(target=warm_up_modules, name="warm-up", daemon=True).start()
diff --git a/request_llm/bridge_all.py b/request_llm/bridge_all.py
index 311dc6f..fddc9a7 100644
--- a/request_llm/bridge_all.py
+++ b/request_llm/bridge_all.py
@@ -11,7 +11,7 @@
import tiktoken
from functools import lru_cache
from concurrent.futures import ThreadPoolExecutor
-from toolbox import get_conf
+from toolbox import get_conf, trimmed_format_exc
from .bridge_chatgpt import predict_no_ui_long_connection as chatgpt_noui
from .bridge_chatgpt import predict as chatgpt_ui
@@ -19,6 +19,9 @@ from .bridge_chatgpt import predict as chatgpt_ui
from .bridge_chatglm import predict_no_ui_long_connection as chatglm_noui
from .bridge_chatglm import predict as chatglm_ui
+from .bridge_newbing import predict_no_ui_long_connection as newbing_noui
+from .bridge_newbing import predict as newbing_ui
+
# from .bridge_tgui import predict_no_ui_long_connection as tgui_noui
# from .bridge_tgui import predict as tgui_ui
@@ -48,6 +51,7 @@ class LazyloadTiktoken(object):
API_URL_REDIRECT, = get_conf("API_URL_REDIRECT")
openai_endpoint = "https://api.openai.com/v1/chat/completions"
api2d_endpoint = "https://openai.api2d.net/v1/chat/completions"
+newbing_endpoint = "wss://sydney.bing.com/sydney/ChatHub"
# 兼容旧版的配置
try:
API_URL, = get_conf("API_URL")
@@ -59,6 +63,7 @@ except:
# 新版配置
if openai_endpoint in API_URL_REDIRECT: openai_endpoint = API_URL_REDIRECT[openai_endpoint]
if api2d_endpoint in API_URL_REDIRECT: api2d_endpoint = API_URL_REDIRECT[api2d_endpoint]
+if newbing_endpoint in API_URL_REDIRECT: newbing_endpoint = API_URL_REDIRECT[newbing_endpoint]
# 获取tokenizer
@@ -116,7 +121,15 @@ model_info = {
"tokenizer": tokenizer_gpt35,
"token_cnt": get_token_num_gpt35,
},
-
+ # newbing
+ "newbing": {
+ "fn_with_ui": newbing_ui,
+ "fn_without_ui": newbing_noui,
+ "endpoint": newbing_endpoint,
+ "max_token": 4096,
+ "tokenizer": tokenizer_gpt35,
+ "token_cnt": get_token_num_gpt35,
+ },
}
@@ -128,10 +141,7 @@ def LLM_CATCH_EXCEPTION(f):
try:
return f(inputs, llm_kwargs, history, sys_prompt, observe_window, console_slience)
except Exception as e:
- from toolbox import get_conf
- import traceback
- proxies, = get_conf('proxies')
- tb_str = '\n```\n' + traceback.format_exc() + '\n```\n'
+ tb_str = '\n```\n' + trimmed_format_exc() + '\n```\n'
observe_window[0] = tb_str
return tb_str
return decorated
@@ -182,7 +192,7 @@ def predict_no_ui_long_connection(inputs, llm_kwargs, history, sys_prompt, obser
def mutex_manager(window_mutex, observe_window):
while True:
- time.sleep(0.5)
+ time.sleep(0.25)
if not window_mutex[-1]: break
# 看门狗(watchdog)
for i in range(n_model):
diff --git a/request_llm/bridge_chatglm.py b/request_llm/bridge_chatglm.py
index fb44043..7c86a22 100644
--- a/request_llm/bridge_chatglm.py
+++ b/request_llm/bridge_chatglm.py
@@ -1,6 +1,7 @@
from transformers import AutoModel, AutoTokenizer
import time
+import threading
import importlib
from toolbox import update_ui, get_conf
from multiprocessing import Process, Pipe
@@ -18,6 +19,7 @@ class GetGLMHandle(Process):
self.success = True
self.check_dependency()
self.start()
+ self.threadLock = threading.Lock()
def check_dependency(self):
try:
@@ -72,6 +74,7 @@ class GetGLMHandle(Process):
def stream_chat(self, **kwargs):
# 主进程执行
+ self.threadLock.acquire()
self.parent.send(kwargs)
while True:
res = self.parent.recv()
@@ -79,7 +82,7 @@ class GetGLMHandle(Process):
yield res
else:
break
- return
+ self.threadLock.release()
global glm_handle
glm_handle = None
@@ -145,10 +148,13 @@ def predict(inputs, llm_kwargs, plugin_kwargs, chatbot, history=[], system_promp
history_feedin.append([history[2*i], history[2*i+1]] )
# 开始接收chatglm的回复
+ response = "[Local Message]: 等待ChatGLM响应中 ..."
for response in glm_handle.stream_chat(query=inputs, history=history_feedin, max_length=llm_kwargs['max_length'], top_p=llm_kwargs['top_p'], temperature=llm_kwargs['temperature']):
chatbot[-1] = (inputs, response)
yield from update_ui(chatbot=chatbot, history=history)
# 总结输出
+ if response == "[Local Message]: 等待ChatGLM响应中 ...":
+ response = "[Local Message]: ChatGLM响应异常 ..."
history.extend([inputs, response])
yield from update_ui(chatbot=chatbot, history=history)
diff --git a/request_llm/bridge_chatgpt.py b/request_llm/bridge_chatgpt.py
index 5e32f45..48eaba0 100644
--- a/request_llm/bridge_chatgpt.py
+++ b/request_llm/bridge_chatgpt.py
@@ -21,7 +21,7 @@ import importlib
# config_private.py放自己的秘密如API和代理网址
# 读取时首先看是否存在私密的config_private配置文件(不受git管控),如果有,则覆盖原config文件
-from toolbox import get_conf, update_ui, is_any_api_key, select_api_key, what_keys, clip_history
+from toolbox import get_conf, update_ui, is_any_api_key, select_api_key, what_keys, clip_history, trimmed_format_exc
proxies, API_KEY, TIMEOUT_SECONDS, MAX_RETRY = \
get_conf('proxies', 'API_KEY', 'TIMEOUT_SECONDS', 'MAX_RETRY')
@@ -215,7 +215,7 @@ def predict(inputs, llm_kwargs, plugin_kwargs, chatbot, history=[], system_promp
chatbot[-1] = (chatbot[-1][0], "[Local Message] Not enough point. API2D账户点数不足.")
else:
from toolbox import regular_txt_to_markdown
- tb_str = '```\n' + traceback.format_exc() + '```'
+ tb_str = '```\n' + trimmed_format_exc() + '```'
chatbot[-1] = (chatbot[-1][0], f"[Local Message] 异常 \n\n{tb_str} \n\n{regular_txt_to_markdown(chunk_decoded[4:])}")
yield from update_ui(chatbot=chatbot, history=history, msg="Json异常" + error_msg) # 刷新界面
return
diff --git a/request_llm/bridge_newbing.py b/request_llm/bridge_newbing.py
new file mode 100644
index 0000000..dca7485
--- /dev/null
+++ b/request_llm/bridge_newbing.py
@@ -0,0 +1,254 @@
+"""
+========================================================================
+第一部分:来自EdgeGPT.py
+https://github.com/acheong08/EdgeGPT
+========================================================================
+"""
+from .edge_gpt import NewbingChatbot
+load_message = "等待NewBing响应。"
+
+"""
+========================================================================
+第二部分:子进程Worker(调用主体)
+========================================================================
+"""
+import time
+import json
+import re
+import logging
+import asyncio
+import importlib
+import threading
+from toolbox import update_ui, get_conf, trimmed_format_exc
+from multiprocessing import Process, Pipe
+
+def preprocess_newbing_out(s):
+ pattern = r'\^(\d+)\^' # 匹配^数字^
+ sub = lambda m: '('+m.group(1)+')' # 将匹配到的数字作为替换值
+ result = re.sub(pattern, sub, s) # 替换操作
+ if '[1]' in result:
+ result += '\n\n```reference\n' + "\n".join([r for r in result.split('\n') if r.startswith('[')]) + '\n```\n'
+ return result
+
+def preprocess_newbing_out_simple(result):
+ if '[1]' in result:
+ result += '\n\n```reference\n' + "\n".join([r for r in result.split('\n') if r.startswith('[')]) + '\n```\n'
+ return result
+
+class NewBingHandle(Process):
+ def __init__(self):
+ super().__init__(daemon=True)
+ self.parent, self.child = Pipe()
+ self.newbing_model = None
+ self.info = ""
+ self.success = True
+ self.local_history = []
+ self.check_dependency()
+ self.start()
+ self.threadLock = threading.Lock()
+
+ def check_dependency(self):
+ try:
+ self.success = False
+ import certifi, httpx, rich
+ self.info = "依赖检测通过,等待NewBing响应。注意目前不能多人同时调用NewBing接口(有线程锁),否则将导致每个人的NewBing问询历史互相渗透。调用NewBing时,会自动使用已配置的代理。"
+ self.success = True
+ except:
+ self.info = "缺少的依赖,如果要使用Newbing,除了基础的pip依赖以外,您还需要运行`pip install -r request_llm/requirements_newbing.txt`安装Newbing的依赖。"
+ self.success = False
+
+ def ready(self):
+ return self.newbing_model is not None
+
+ async def async_run(self):
+ # 读取配置
+ NEWBING_STYLE, = get_conf('NEWBING_STYLE')
+ from request_llm.bridge_all import model_info
+ endpoint = model_info['newbing']['endpoint']
+ while True:
+ # 等待
+ kwargs = self.child.recv()
+ question=kwargs['query']
+ history=kwargs['history']
+ system_prompt=kwargs['system_prompt']
+
+ # 是否重置
+ if len(self.local_history) > 0 and len(history)==0:
+ await self.newbing_model.reset()
+ self.local_history = []
+
+ # 开始问问题
+ prompt = ""
+ if system_prompt not in self.local_history:
+ self.local_history.append(system_prompt)
+ prompt += system_prompt + '\n'
+
+ # 追加历史
+ for ab in history:
+ a, b = ab
+ if a not in self.local_history:
+ self.local_history.append(a)
+ prompt += a + '\n'
+ # if b not in self.local_history:
+ # self.local_history.append(b)
+ # prompt += b + '\n'
+
+ # 问题
+ prompt += question
+ self.local_history.append(question)
+ print('question:', prompt)
+ # 提交
+ async for final, response in self.newbing_model.ask_stream(
+ prompt=question,
+ conversation_style=NEWBING_STYLE, # ["creative", "balanced", "precise"]
+ wss_link=endpoint, # "wss://sydney.bing.com/sydney/ChatHub"
+ ):
+ if not final:
+ print(response)
+ self.child.send(str(response))
+ else:
+ print('-------- receive final ---------')
+ self.child.send('[Finish]')
+ # self.local_history.append(response)
+
+
+ def run(self):
+ """
+ 这个函数运行在子进程
+ """
+ # 第一次运行,加载参数
+ self.success = False
+ self.local_history = []
+ if (self.newbing_model is None) or (not self.success):
+ # 代理设置
+ proxies, = get_conf('proxies')
+ if proxies is None:
+ self.proxies_https = None
+ else:
+ self.proxies_https = proxies['https']
+ # cookie
+ NEWBING_COOKIES, = get_conf('NEWBING_COOKIES')
+ try:
+ cookies = json.loads(NEWBING_COOKIES)
+ except:
+ self.success = False
+ tb_str = '\n```\n' + trimmed_format_exc() + '\n```\n'
+ self.child.send(f'[Local Message] 不能加载Newbing组件。NEWBING_COOKIES未填写或有格式错误。')
+ self.child.send('[Fail]')
+ self.child.send('[Finish]')
+ raise RuntimeError(f"不能加载Newbing组件。NEWBING_COOKIES未填写或有格式错误。")
+
+ try:
+ self.newbing_model = NewbingChatbot(proxy=self.proxies_https, cookies=cookies)
+ except:
+ self.success = False
+ tb_str = '\n```\n' + trimmed_format_exc() + '\n```\n'
+ self.child.send(f'[Local Message] 不能加载Newbing组件。{tb_str}')
+ self.child.send('[Fail]')
+ self.child.send('[Finish]')
+ raise RuntimeError(f"不能加载Newbing组件。")
+
+ self.success = True
+ try:
+ # 进入任务等待状态
+ asyncio.run(self.async_run())
+ except Exception:
+ tb_str = '```\n' + trimmed_format_exc() + '```'
+ self.child.send(f'[Local Message] Newbing失败 {tb_str}.')
+ self.child.send('[Fail]')
+ self.child.send('[Finish]')
+
+ def stream_chat(self, **kwargs):
+ """
+ 这个函数运行在主进程
+ """
+ self.threadLock.acquire()
+ self.parent.send(kwargs) # 发送请求到子进程
+ while True:
+ res = self.parent.recv() # 等待newbing回复的片段
+ if res == '[Finish]':
+ break # 结束
+ elif res == '[Fail]':
+ self.success = False
+ break
+ else:
+ yield res # newbing回复的片段
+ self.threadLock.release()
+
+
+"""
+========================================================================
+第三部分:主进程统一调用函数接口
+========================================================================
+"""
+global newbing_handle
+newbing_handle = None
+
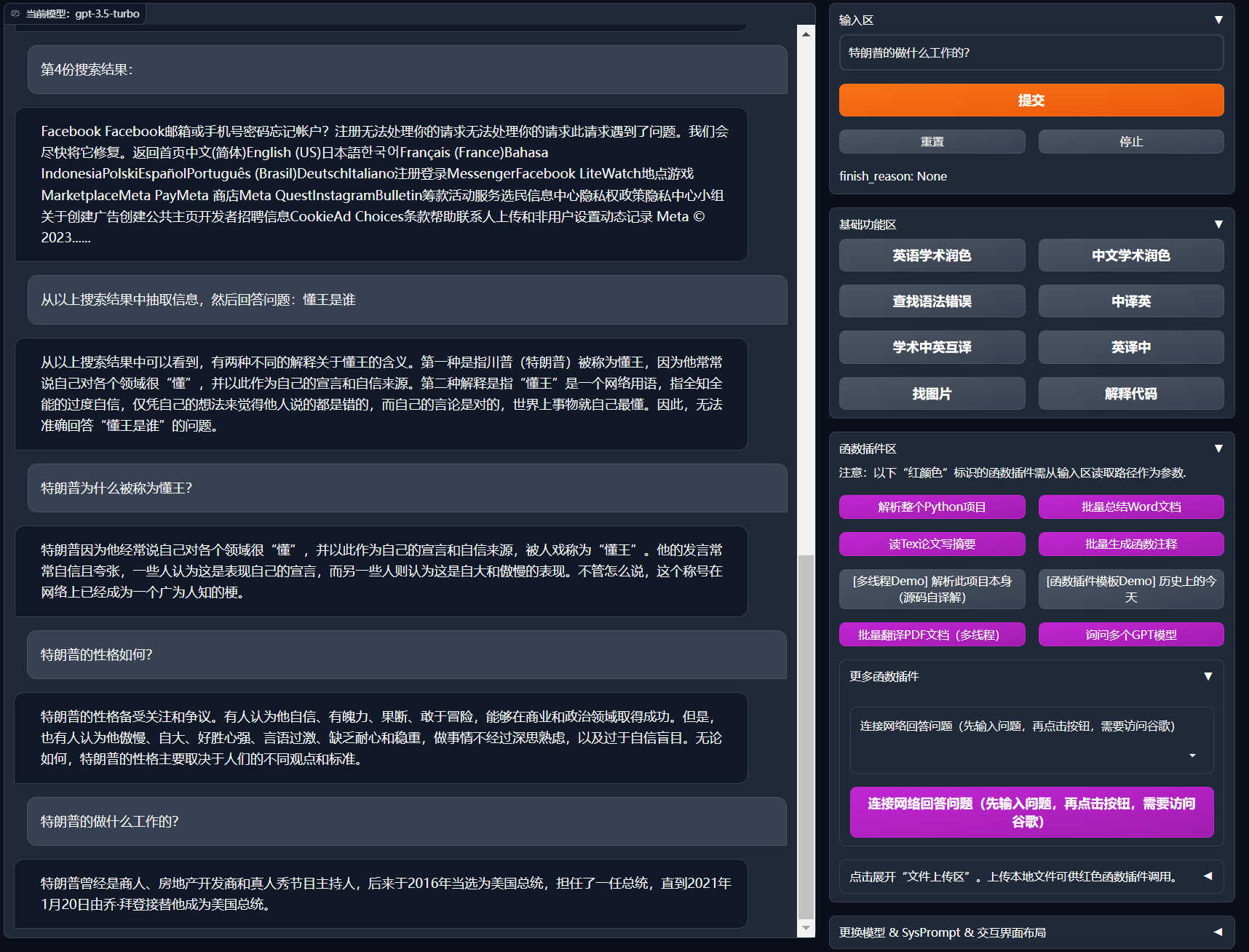
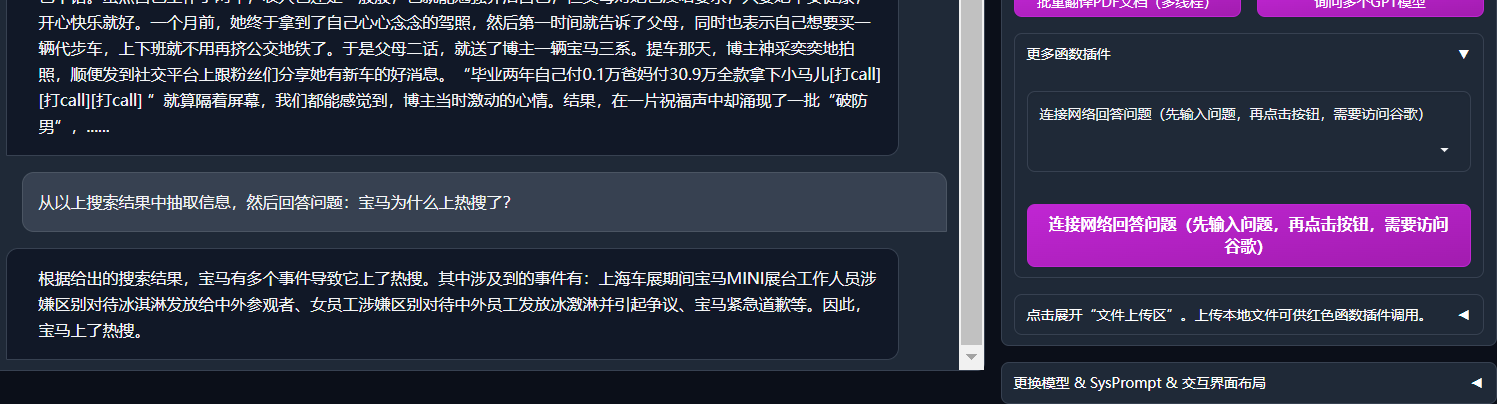
+def predict_no_ui_long_connection(inputs, llm_kwargs, history=[], sys_prompt="", observe_window=None, console_slience=False):
+ """
+ 多线程方法
+ 函数的说明请见 request_llm/bridge_all.py
+ """
+ global newbing_handle
+ if (newbing_handle is None) or (not newbing_handle.success):
+ newbing_handle = NewBingHandle()
+ observe_window[0] = load_message + "\n\n" + newbing_handle.info
+ if not newbing_handle.success:
+ error = newbing_handle.info
+ newbing_handle = None
+ raise RuntimeError(error)
+
+ # 没有 sys_prompt 接口,因此把prompt加入 history
+ history_feedin = []
+ for i in range(len(history)//2):
+ history_feedin.append([history[2*i], history[2*i+1]] )
+
+ watch_dog_patience = 5 # 看门狗 (watchdog) 的耐心, 设置5秒即可
+ response = ""
+ observe_window[0] = "[Local Message]: 等待NewBing响应中 ..."
+ for response in newbing_handle.stream_chat(query=inputs, history=history_feedin, system_prompt=sys_prompt, max_length=llm_kwargs['max_length'], top_p=llm_kwargs['top_p'], temperature=llm_kwargs['temperature']):
+ observe_window[0] = preprocess_newbing_out_simple(response)
+ if len(observe_window) >= 2:
+ if (time.time()-observe_window[1]) > watch_dog_patience:
+ raise RuntimeError("程序终止。")
+ return preprocess_newbing_out_simple(response)
+
+def predict(inputs, llm_kwargs, plugin_kwargs, chatbot, history=[], system_prompt='', stream = True, additional_fn=None):
+ """
+ 单线程方法
+ 函数的说明请见 request_llm/bridge_all.py
+ """
+ chatbot.append((inputs, "[Local Message]: 等待NewBing响应中 ..."))
+
+ global newbing_handle
+ if (newbing_handle is None) or (not newbing_handle.success):
+ newbing_handle = NewBingHandle()
+ chatbot[-1] = (inputs, load_message + "\n\n" + newbing_handle.info)
+ yield from update_ui(chatbot=chatbot, history=[])
+ if not newbing_handle.success:
+ newbing_handle = None
+ return
+
+ if additional_fn is not None:
+ import core_functional
+ importlib.reload(core_functional) # 热更新prompt
+ core_functional = core_functional.get_core_functions()
+ if "PreProcess" in core_functional[additional_fn]: inputs = core_functional[additional_fn]["PreProcess"](inputs) # 获取预处理函数(如果有的话)
+ inputs = core_functional[additional_fn]["Prefix"] + inputs + core_functional[additional_fn]["Suffix"]
+
+ history_feedin = []
+ for i in range(len(history)//2):
+ history_feedin.append([history[2*i], history[2*i+1]] )
+
+ chatbot[-1] = (inputs, "[Local Message]: 等待NewBing响应中 ...")
+ response = "[Local Message]: 等待NewBing响应中 ..."
+ yield from update_ui(chatbot=chatbot, history=history, msg="NewBing响应缓慢,尚未完成全部响应,请耐心完成后再提交新问题。")
+ for response in newbing_handle.stream_chat(query=inputs, history=history_feedin, system_prompt=system_prompt, max_length=llm_kwargs['max_length'], top_p=llm_kwargs['top_p'], temperature=llm_kwargs['temperature']):
+ chatbot[-1] = (inputs, preprocess_newbing_out(response))
+ yield from update_ui(chatbot=chatbot, history=history, msg="NewBing响应缓慢,尚未完成全部响应,请耐心完成后再提交新问题。")
+ if response == "[Local Message]: 等待NewBing响应中 ...": response = "[Local Message]: NewBing响应异常,请刷新界面重试 ..."
+ history.extend([inputs, response])
+ logging.info(f'[raw_input] {inputs}')
+ logging.info(f'[response] {response}')
+ yield from update_ui(chatbot=chatbot, history=history, msg="完成全部响应,请提交新问题。")
+
diff --git a/request_llm/edge_gpt.py b/request_llm/edge_gpt.py
new file mode 100644
index 0000000..bbf8400
--- /dev/null
+++ b/request_llm/edge_gpt.py
@@ -0,0 +1,409 @@
+"""
+========================================================================
+第一部分:来自EdgeGPT.py
+https://github.com/acheong08/EdgeGPT
+========================================================================
+"""
+
+import argparse
+import asyncio
+import json
+import os
+import random
+import re
+import ssl
+import sys
+import uuid
+from enum import Enum
+from typing import Generator
+from typing import Literal
+from typing import Optional
+from typing import Union
+import websockets.client as websockets
+
+DELIMITER = "\x1e"
+
+
+# Generate random IP between range 13.104.0.0/14
+FORWARDED_IP = (
+ f"13.{random.randint(104, 107)}.{random.randint(0, 255)}.{random.randint(0, 255)}"
+)
+
+HEADERS = {
+ "accept": "application/json",
+ "accept-language": "en-US,en;q=0.9",
+ "content-type": "application/json",
+ "sec-ch-ua": '"Not_A Brand";v="99", "Microsoft Edge";v="110", "Chromium";v="110"',
+ "sec-ch-ua-arch": '"x86"',
+ "sec-ch-ua-bitness": '"64"',
+ "sec-ch-ua-full-version": '"109.0.1518.78"',
+ "sec-ch-ua-full-version-list": '"Chromium";v="110.0.5481.192", "Not A(Brand";v="24.0.0.0", "Microsoft Edge";v="110.0.1587.69"',
+ "sec-ch-ua-mobile": "?0",
+ "sec-ch-ua-model": "",
+ "sec-ch-ua-platform": '"Windows"',
+ "sec-ch-ua-platform-version": '"15.0.0"',
+ "sec-fetch-dest": "empty",
+ "sec-fetch-mode": "cors",
+ "sec-fetch-site": "same-origin",
+ "x-ms-client-request-id": str(uuid.uuid4()),
+ "x-ms-useragent": "azsdk-js-api-client-factory/1.0.0-beta.1 core-rest-pipeline/1.10.0 OS/Win32",
+ "Referer": "https://www.bing.com/search?q=Bing+AI&showconv=1&FORM=hpcodx",
+ "Referrer-Policy": "origin-when-cross-origin",
+ "x-forwarded-for": FORWARDED_IP,
+}
+
+HEADERS_INIT_CONVER = {
+ "authority": "edgeservices.bing.com",
+ "accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7",
+ "accept-language": "en-US,en;q=0.9",
+ "cache-control": "max-age=0",
+ "sec-ch-ua": '"Chromium";v="110", "Not A(Brand";v="24", "Microsoft Edge";v="110"',
+ "sec-ch-ua-arch": '"x86"',
+ "sec-ch-ua-bitness": '"64"',
+ "sec-ch-ua-full-version": '"110.0.1587.69"',
+ "sec-ch-ua-full-version-list": '"Chromium";v="110.0.5481.192", "Not A(Brand";v="24.0.0.0", "Microsoft Edge";v="110.0.1587.69"',
+ "sec-ch-ua-mobile": "?0",
+ "sec-ch-ua-model": '""',
+ "sec-ch-ua-platform": '"Windows"',
+ "sec-ch-ua-platform-version": '"15.0.0"',
+ "sec-fetch-dest": "document",
+ "sec-fetch-mode": "navigate",
+ "sec-fetch-site": "none",
+ "sec-fetch-user": "?1",
+ "upgrade-insecure-requests": "1",
+ "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36 Edg/110.0.1587.69",
+ "x-edge-shopping-flag": "1",
+ "x-forwarded-for": FORWARDED_IP,
+}
+
+def get_ssl_context():
+ import certifi
+ ssl_context = ssl.create_default_context()
+ ssl_context.load_verify_locations(certifi.where())
+ return ssl_context
+
+
+
+class NotAllowedToAccess(Exception):
+ pass
+
+
+class ConversationStyle(Enum):
+ creative = "h3imaginative,clgalileo,gencontentv3"
+ balanced = "galileo"
+ precise = "h3precise,clgalileo"
+
+
+CONVERSATION_STYLE_TYPE = Optional[
+ Union[ConversationStyle, Literal["creative", "balanced", "precise"]]
+]
+
+
+def _append_identifier(msg: dict) -> str:
+ """
+ Appends special character to end of message to identify end of message
+ """
+ # Convert dict to json string
+ return json.dumps(msg) + DELIMITER
+
+
+def _get_ran_hex(length: int = 32) -> str:
+ """
+ Returns random hex string
+ """
+ return "".join(random.choice("0123456789abcdef") for _ in range(length))
+
+
+class _ChatHubRequest:
+ """
+ Request object for ChatHub
+ """
+
+ def __init__(
+ self,
+ conversation_signature: str,
+ client_id: str,
+ conversation_id: str,
+ invocation_id: int = 0,
+ ) -> None:
+ self.struct: dict = {}
+
+ self.client_id: str = client_id
+ self.conversation_id: str = conversation_id
+ self.conversation_signature: str = conversation_signature
+ self.invocation_id: int = invocation_id
+
+ def update(
+ self,
+ prompt,
+ conversation_style,
+ options,
+ ) -> None:
+ """
+ Updates request object
+ """
+ if options is None:
+ options = [
+ "deepleo",
+ "enable_debug_commands",
+ "disable_emoji_spoken_text",
+ "enablemm",
+ ]
+ if conversation_style:
+ if not isinstance(conversation_style, ConversationStyle):
+ conversation_style = getattr(ConversationStyle, conversation_style)
+ options = [
+ "nlu_direct_response_filter",
+ "deepleo",
+ "disable_emoji_spoken_text",
+ "responsible_ai_policy_235",
+ "enablemm",
+ conversation_style.value,
+ "dtappid",
+ "cricinfo",
+ "cricinfov2",
+ "dv3sugg",
+ ]
+ self.struct = {
+ "arguments": [
+ {
+ "source": "cib",
+ "optionsSets": options,
+ "sliceIds": [
+ "222dtappid",
+ "225cricinfo",
+ "224locals0",
+ ],
+ "traceId": _get_ran_hex(32),
+ "isStartOfSession": self.invocation_id == 0,
+ "message": {
+ "author": "user",
+ "inputMethod": "Keyboard",
+ "text": prompt,
+ "messageType": "Chat",
+ },
+ "conversationSignature": self.conversation_signature,
+ "participant": {
+ "id": self.client_id,
+ },
+ "conversationId": self.conversation_id,
+ },
+ ],
+ "invocationId": str(self.invocation_id),
+ "target": "chat",
+ "type": 4,
+ }
+ self.invocation_id += 1
+
+
+class _Conversation:
+ """
+ Conversation API
+ """
+
+ def __init__(
+ self,
+ cookies,
+ proxy,
+ ) -> None:
+ self.struct: dict = {
+ "conversationId": None,
+ "clientId": None,
+ "conversationSignature": None,
+ "result": {"value": "Success", "message": None},
+ }
+ import httpx
+ self.proxy = proxy
+ proxy = (
+ proxy
+ or os.environ.get("all_proxy")
+ or os.environ.get("ALL_PROXY")
+ or os.environ.get("https_proxy")
+ or os.environ.get("HTTPS_PROXY")
+ or None
+ )
+ if proxy is not None and proxy.startswith("socks5h://"):
+ proxy = "socks5://" + proxy[len("socks5h://") :]
+ self.session = httpx.Client(
+ proxies=proxy,
+ timeout=30,
+ headers=HEADERS_INIT_CONVER,
+ )
+ for cookie in cookies:
+ self.session.cookies.set(cookie["name"], cookie["value"])
+
+ # Send GET request
+ response = self.session.get(
+ url=os.environ.get("BING_PROXY_URL")
+ or "https://edgeservices.bing.com/edgesvc/turing/conversation/create",
+ )
+ if response.status_code != 200:
+ response = self.session.get(
+ "https://edge.churchless.tech/edgesvc/turing/conversation/create",
+ )
+ if response.status_code != 200:
+ print(f"Status code: {response.status_code}")
+ print(response.text)
+ print(response.url)
+ raise Exception("Authentication failed")
+ try:
+ self.struct = response.json()
+ except (json.decoder.JSONDecodeError, NotAllowedToAccess) as exc:
+ raise Exception(
+ "Authentication failed. You have not been accepted into the beta.",
+ ) from exc
+ if self.struct["result"]["value"] == "UnauthorizedRequest":
+ raise NotAllowedToAccess(self.struct["result"]["message"])
+
+
+class _ChatHub:
+ """
+ Chat API
+ """
+
+ def __init__(self, conversation) -> None:
+ self.wss = None
+ self.request: _ChatHubRequest
+ self.loop: bool
+ self.task: asyncio.Task
+ print(conversation.struct)
+ self.request = _ChatHubRequest(
+ conversation_signature=conversation.struct["conversationSignature"],
+ client_id=conversation.struct["clientId"],
+ conversation_id=conversation.struct["conversationId"],
+ )
+
+ async def ask_stream(
+ self,
+ prompt: str,
+ wss_link: str,
+ conversation_style: CONVERSATION_STYLE_TYPE = None,
+ raw: bool = False,
+ options: dict = None,
+ ) -> Generator[str, None, None]:
+ """
+ Ask a question to the bot
+ """
+ if self.wss and not self.wss.closed:
+ await self.wss.close()
+ # Check if websocket is closed
+ self.wss = await websockets.connect(
+ wss_link,
+ extra_headers=HEADERS,
+ max_size=None,
+ ssl=get_ssl_context()
+ )
+ await self._initial_handshake()
+ # Construct a ChatHub request
+ self.request.update(
+ prompt=prompt,
+ conversation_style=conversation_style,
+ options=options,
+ )
+ # Send request
+ await self.wss.send(_append_identifier(self.request.struct))
+ final = False
+ while not final:
+ objects = str(await self.wss.recv()).split(DELIMITER)
+ for obj in objects:
+ if obj is None or not obj:
+ continue
+ response = json.loads(obj)
+ if response.get("type") != 2 and raw:
+ yield False, response
+ elif response.get("type") == 1 and response["arguments"][0].get(
+ "messages",
+ ):
+ resp_txt = response["arguments"][0]["messages"][0]["adaptiveCards"][
+ 0
+ ]["body"][0].get("text")
+ yield False, resp_txt
+ elif response.get("type") == 2:
+ final = True
+ yield True, response
+
+ async def _initial_handshake(self) -> None:
+ await self.wss.send(_append_identifier({"protocol": "json", "version": 1}))
+ await self.wss.recv()
+
+ async def close(self) -> None:
+ """
+ Close the connection
+ """
+ if self.wss and not self.wss.closed:
+ await self.wss.close()
+
+
+class NewbingChatbot:
+ """
+ Combines everything to make it seamless
+ """
+
+ def __init__(
+ self,
+ cookies,
+ proxy
+ ) -> None:
+ if cookies is None:
+ cookies = {}
+ self.cookies = cookies
+ self.proxy = proxy
+ self.chat_hub: _ChatHub = _ChatHub(
+ _Conversation(self.cookies, self.proxy),
+ )
+
+ async def ask(
+ self,
+ prompt: str,
+ wss_link: str,
+ conversation_style: CONVERSATION_STYLE_TYPE = None,
+ options: dict = None,
+ ) -> dict:
+ """
+ Ask a question to the bot
+ """
+ async for final, response in self.chat_hub.ask_stream(
+ prompt=prompt,
+ conversation_style=conversation_style,
+ wss_link=wss_link,
+ options=options,
+ ):
+ if final:
+ return response
+ await self.chat_hub.wss.close()
+ return None
+
+ async def ask_stream(
+ self,
+ prompt: str,
+ wss_link: str,
+ conversation_style: CONVERSATION_STYLE_TYPE = None,
+ raw: bool = False,
+ options: dict = None,
+ ) -> Generator[str, None, None]:
+ """
+ Ask a question to the bot
+ """
+ async for response in self.chat_hub.ask_stream(
+ prompt=prompt,
+ conversation_style=conversation_style,
+ wss_link=wss_link,
+ raw=raw,
+ options=options,
+ ):
+ yield response
+
+ async def close(self) -> None:
+ """
+ Close the connection
+ """
+ await self.chat_hub.close()
+
+ async def reset(self) -> None:
+ """
+ Reset the conversation
+ """
+ await self.close()
+ self.chat_hub = _ChatHub(_Conversation(self.cookies, self.proxy))
+
+
diff --git a/request_llm/requirements_newbing.txt b/request_llm/requirements_newbing.txt
new file mode 100644
index 0000000..73455f4
--- /dev/null
+++ b/request_llm/requirements_newbing.txt
@@ -0,0 +1,8 @@
+BingImageCreator
+certifi
+httpx
+prompt_toolkit
+requests
+rich
+websockets
+httpx[socks]
diff --git a/toolbox.py b/toolbox.py
index c9dc207..5e42164 100644
--- a/toolbox.py
+++ b/toolbox.py
@@ -5,7 +5,20 @@ import inspect
import re
from latex2mathml.converter import convert as tex2mathml
from functools import wraps, lru_cache
-############################### 插件输入输出接驳区 #######################################
+
+"""
+========================================================================
+第一部分
+函数插件输入输出接驳区
+ - ChatBotWithCookies: 带Cookies的Chatbot类,为实现更多强大的功能做基础
+ - ArgsGeneralWrapper: 装饰器函数,用于重组输入参数,改变输入参数的顺序与结构
+ - update_ui: 刷新界面用 yield from update_ui(chatbot, history)
+ - CatchException: 将插件中出的所有问题显示在界面上
+ - HotReload: 实现插件的热更新
+ - trimmed_format_exc: 打印traceback,为了安全而隐藏绝对地址
+========================================================================
+"""
+
class ChatBotWithCookies(list):
def __init__(self, cookie):
self._cookies = cookie
@@ -20,6 +33,7 @@ class ChatBotWithCookies(list):
def get_cookies(self):
return self._cookies
+
def ArgsGeneralWrapper(f):
"""
装饰器函数,用于重组输入参数,改变输入参数的顺序与结构。
@@ -47,6 +61,7 @@ def ArgsGeneralWrapper(f):
yield from f(txt_passon, llm_kwargs, plugin_kwargs, chatbot_with_cookie, history, system_prompt, *args)
return decorated
+
def update_ui(chatbot, history, msg='正常', **kwargs): # 刷新界面
"""
刷新用户界面
@@ -54,10 +69,18 @@ def update_ui(chatbot, history, msg='正常', **kwargs): # 刷新界面
assert isinstance(chatbot, ChatBotWithCookies), "在传递chatbot的过程中不要将其丢弃。必要时,可用clear将其清空,然后用for+append循环重新赋值。"
yield chatbot.get_cookies(), chatbot, history, msg
+def trimmed_format_exc():
+ import os, traceback
+ str = traceback.format_exc()
+ current_path = os.getcwd()
+ replace_path = "."
+ return str.replace(current_path, replace_path)
+
def CatchException(f):
"""
装饰器函数,捕捉函数f中的异常并封装到一个生成器中返回,并显示到聊天当中。
"""
+
@wraps(f)
def decorated(txt, top_p, temperature, chatbot, history, systemPromptTxt, WEB_PORT):
try:
@@ -66,9 +89,10 @@ def CatchException(f):
from check_proxy import check_proxy
from toolbox import get_conf
proxies, = get_conf('proxies')
- tb_str = '```\n' + traceback.format_exc() + '```'
- if chatbot is None or len(chatbot) == 0:
- chatbot = [["插件调度异常", "异常原因"]]
+ tb_str = '```\n' + trimmed_format_exc() + '```'
+ if len(chatbot) == 0:
+ chatbot.clear()
+ chatbot.append(["插件调度异常", "异常原因"])
chatbot[-1] = (chatbot[-1][0],
f"[Local Message] 实验性函数调用出错: \n\n{tb_str} \n\n当前代理可用性: \n\n{check_proxy(proxies)}")
yield from update_ui(chatbot=chatbot, history=history, msg=f'异常 {e}') # 刷新界面
@@ -93,7 +117,23 @@ def HotReload(f):
return decorated
-####################################### 其他小工具 #####################################
+"""
+========================================================================
+第二部分
+其他小工具:
+ - write_results_to_file: 将结果写入markdown文件中
+ - regular_txt_to_markdown: 将普通文本转换为Markdown格式的文本。
+ - report_execption: 向chatbot中添加简单的意外错误信息
+ - text_divide_paragraph: 将文本按照段落分隔符分割开,生成带有段落标签的HTML代码。
+ - markdown_convertion: 用多种方式组合,将markdown转化为好看的html
+ - format_io: 接管gradio默认的markdown处理方式
+ - on_file_uploaded: 处理文件的上传(自动解压)
+ - on_report_generated: 将生成的报告自动投射到文件上传区
+ - clip_history: 当历史上下文过长时,自动截断
+ - get_conf: 获取设置
+ - select_api_key: 根据当前的模型类别,抽取可用的api-key
+========================================================================
+"""
def get_reduce_token_percent(text):
"""
@@ -113,7 +153,6 @@ def get_reduce_token_percent(text):
return 0.5, '不详'
-
def write_results_to_file(history, file_name=None):
"""
将对话记录history以Markdown格式写入文件中。如果没有指定文件名,则使用当前时间生成文件名。
@@ -178,13 +217,17 @@ def text_divide_paragraph(text):
text = "".join(lines)
return text
-
+@lru_cache(maxsize=128) # 使用 lru缓存 加快转换速度
def markdown_convertion(txt):
"""
将Markdown格式的文本转换为HTML格式。如果包含数学公式,则先将公式转换为HTML格式。
"""
pre = ''
suf = '
'
+ if txt.startswith(pre) and txt.endswith(suf):
+ # print('警告,输入了已经经过转化的字符串,二次转化可能出问题')
+ return txt # 已经被转化过,不需要再次转化
+
markdown_extension_configs = {
'mdx_math': {
'enable_dollar_delimiter': True,
@@ -228,8 +271,14 @@ def markdown_convertion(txt):
content = content.replace('\n', '')
return content
+ def no_code(txt):
+ if '```' not in txt:
+ return True
+ else:
+ if '```reference' in txt: return True # newbing
+ else: return False
- if ('$' in txt) and ('```' not in txt): # 有$标识的公式符号,且没有代码段```的标识
+ if ('$' in txt) and no_code(txt): # 有$标识的公式符号,且没有代码段```的标识
# convert everything to html format
split = markdown.markdown(text='---')
convert_stage_1 = markdown.markdown(text=txt, extensions=['mdx_math', 'fenced_code', 'tables', 'sane_lists'], extension_configs=markdown_extension_configs)
@@ -369,6 +418,9 @@ def find_recent_files(directory):
def on_file_uploaded(files, chatbot, txt, txt2, checkboxes):
+ """
+ 当文件被上传时的回调函数
+ """
if len(files) == 0:
return chatbot, txt
import shutil
@@ -388,8 +440,7 @@ def on_file_uploaded(files, chatbot, txt, txt2, checkboxes):
shutil.copy(file.name, f'private_upload/{time_tag}/{file_origin_name}')
err_msg += extract_archive(f'private_upload/{time_tag}/{file_origin_name}',
dest_dir=f'private_upload/{time_tag}/{file_origin_name}.extract')
- moved_files = [fp for fp in glob.glob(
- 'private_upload/**/*', recursive=True)]
+ moved_files = [fp for fp in glob.glob('private_upload/**/*', recursive=True)]
if "底部输入区" in checkboxes:
txt = ""
txt2 = f'private_upload/{time_tag}'
@@ -414,8 +465,9 @@ def on_report_generated(files, chatbot):
return report_files, chatbot
def is_openai_api_key(key):
- API_MATCH = re.match(r"sk-[a-zA-Z0-9]{48}$", key)
- return bool(API_MATCH)
+ API_MATCH_ORIGINAL = re.match(r"sk-[a-zA-Z0-9]{48}$", key)
+ API_MATCH_AZURE = re.match(r"[a-zA-Z0-9]{32}$", key)
+ return bool(API_MATCH_ORIGINAL) or bool(API_MATCH_AZURE)
def is_api2d_key(key):
if key.startswith('fk') and len(key) == 41:
@@ -508,7 +560,7 @@ def clear_line_break(txt):
class DummyWith():
"""
这段代码定义了一个名为DummyWith的空上下文管理器,
- 它的作用是……额……没用,即在代码结构不变得情况下取代其他的上下文管理器。
+ 它的作用是……额……就是不起作用,即在代码结构不变得情况下取代其他的上下文管理器。
上下文管理器是一种Python对象,用于与with语句一起使用,
以确保一些资源在代码块执行期间得到正确的初始化和清理。
上下文管理器必须实现两个方法,分别为 __enter__()和 __exit__()。
@@ -522,6 +574,9 @@ class DummyWith():
return
def run_gradio_in_subpath(demo, auth, port, custom_path):
+ """
+ 把gradio的运行地址更改到指定的二次路径上
+ """
def is_path_legal(path: str)->bool:
'''
check path for sub url
diff --git a/version b/version
index a2a877b..73ec974 100644
--- a/version
+++ b/version
@@ -1,5 +1,5 @@
{
- "version": 3.2,
+ "version": 3.32,
"show_feature": true,
- "new_feature": "保存对话功能 <-> 解读任意语言代码+同时询问任意的LLM组合 <-> 添加联网(Google)回答问题插件 <-> 修复ChatGLM上下文BUG <-> 添加支持清华ChatGLM和GPT-4 <-> 改进架构,支持与多个LLM模型同时对话 <-> 添加支持API2D(国内,可支持gpt4)"
+ "new_feature": "完善对话历史的保存/载入/删除 <-> 我们发现了自动更新模块的BUG,此次更新可能需要您手动到Github下载新版程序并覆盖 <-> ChatGLM加线程锁提高并发稳定性 <-> 支持NewBing <-> Markdown翻译功能支持直接输入Readme文件网址 <-> 保存对话功能 <-> 解读任意语言代码+同时询问任意的LLM组合 <-> 添加联网(Google)回答问题插件 <-> 修复ChatGLM上下文BUG <-> 添加支持清华ChatGLM"
}





 -
- -
+
-
+