diff --git a/.gitignore b/.gitignore
index 1bb5ae1..76a9c2b 100644
--- a/.gitignore
+++ b/.gitignore
@@ -145,3 +145,4 @@ cradle*
debug*
private*
crazy_functions/test_project/pdf_and_word
+crazy_functions/test_samples
diff --git a/README.md b/README.md
index e409d56..a77ffc8 100644
--- a/README.md
+++ b/README.md
@@ -173,6 +173,8 @@ docker run --rm -it --net=host --gpus=all gpt-academic bash
2. 使用WSL2(Windows Subsystem for Linux 子系统)
请访问[部署wiki-2](https://github.com/binary-husky/chatgpt_academic/wiki/%E4%BD%BF%E7%94%A8WSL2%EF%BC%88Windows-Subsystem-for-Linux-%E5%AD%90%E7%B3%BB%E7%BB%9F%EF%BC%89%E9%83%A8%E7%BD%B2)
+3. 如何在二级网址(如`http://localhost/subpath`)下运行
+请访问[FastAPI运行说明](docs/WithFastapi.md)
## 安装-代理配置
1. 常规方法
@@ -268,6 +270,8 @@ docker run --rm -it --net=host --gpus=all gpt-academic bash
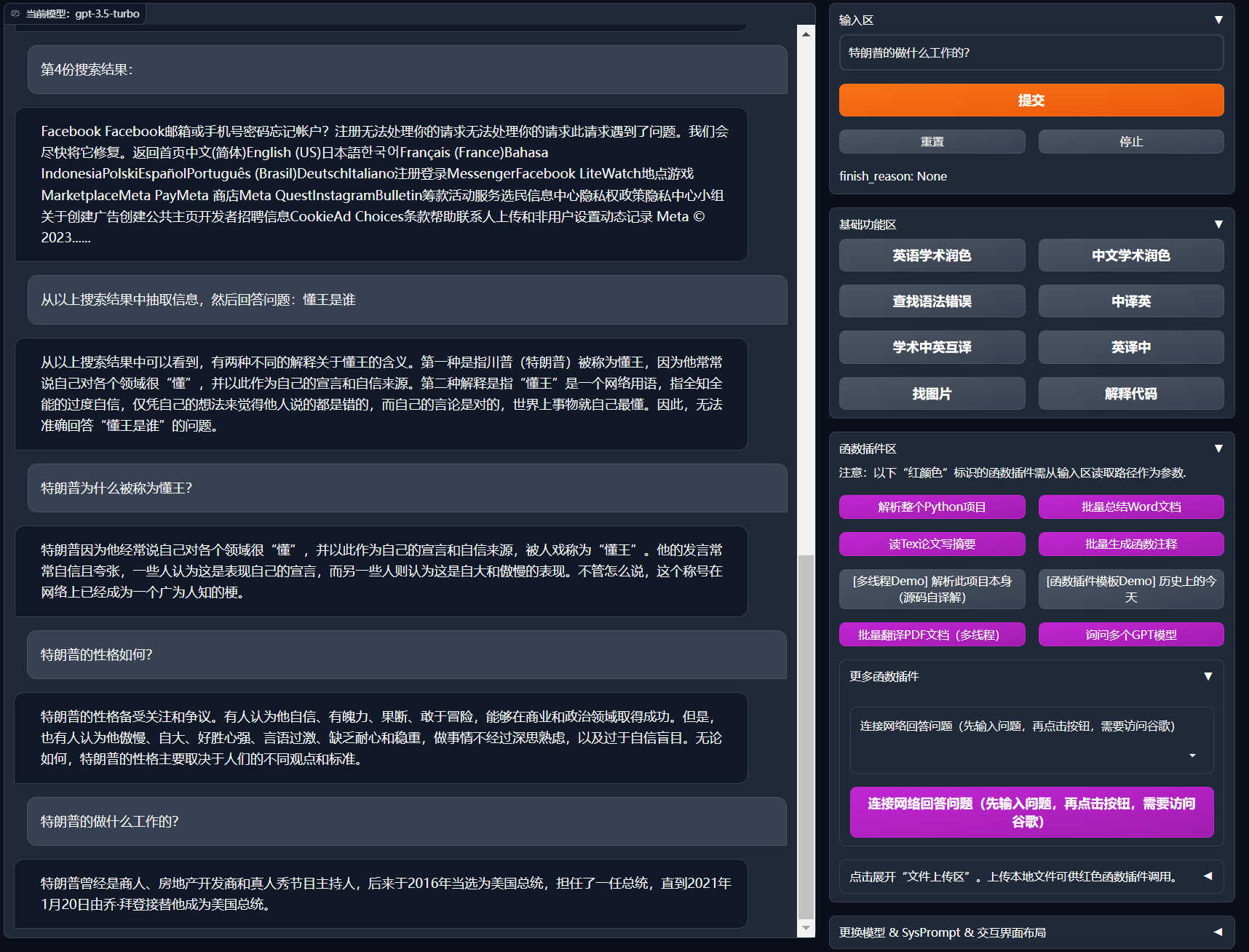
+
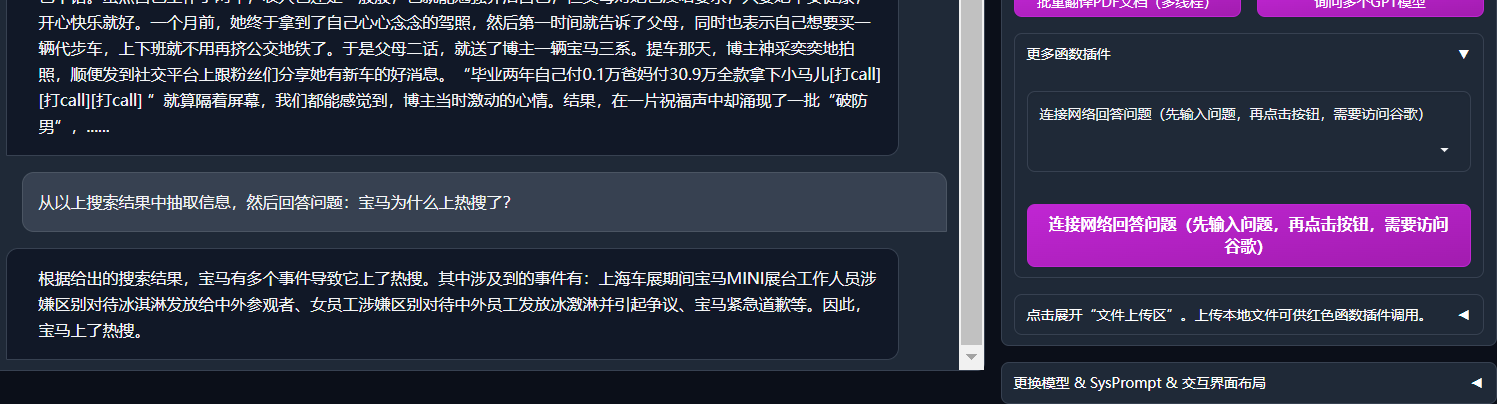
+
diff --git a/config.py b/config.py
index e24c68b..b2727da 100644
--- a/config.py
+++ b/config.py
@@ -56,3 +56,10 @@ CONCURRENT_COUNT = 100
# 设置用户名和密码(不需要修改)(相关功能不稳定,与gradio版本和网络都相关,如果本地使用不建议加这个)
# [("username", "password"), ("username2", "password2"), ...]
AUTHENTICATION = []
+
+# 重新URL重新定向,实现更换API_URL的作用(常规情况下,不要修改!!)
+# 格式 {"https://api.openai.com/v1/chat/completions": "重定向的URL"}
+API_URL_REDIRECT = {}
+
+# 如果需要在二级路径下运行(常规情况下,不要修改!!)(需要配合修改main.py才能生效!)
+CUSTOM_PATH = "/"
diff --git a/crazy_functional.py b/crazy_functional.py
index eb245f2..f49dc23 100644
--- a/crazy_functional.py
+++ b/crazy_functional.py
@@ -20,6 +20,7 @@ def get_crazy_functions():
from crazy_functions.解析项目源代码 import 解析一个CSharp项目
from crazy_functions.总结word文档 import 总结word文档
from crazy_functions.辅助回答 import 猜你想问
+ from crazy_functions.解析JupyterNotebook import 解析ipynb文件
function_plugins = {
"猜你想问": {
"Function": HotReload(猜你想问)
@@ -28,6 +29,11 @@ def get_crazy_functions():
"Color": "stop", # 按钮颜色
"Function": HotReload(解析一个Python项目)
},
+ "[测试功能] 解析Jupyter Notebook文件": {
+ "Color": "stop",
+ "AsButton":False,
+ "Function": HotReload(解析ipynb文件),
+ },
"批量总结Word文档": {
"Color": "stop",
"Function": HotReload(总结word文档)
@@ -172,7 +178,7 @@ def get_crazy_functions():
"AsButton": False, # 加入下拉菜单中
"Function": HotReload(Markdown英译中)
},
-
+
})
###################### 第三组插件 ###########################
@@ -185,7 +191,7 @@ def get_crazy_functions():
"Function": HotReload(下载arxiv论文并翻译摘要)
}
})
-
+
from crazy_functions.联网的ChatGPT import 连接网络回答问题
function_plugins.update({
"连接网络回答问题(先输入问题,再点击按钮,需要访问谷歌)": {
@@ -195,5 +201,25 @@ def get_crazy_functions():
}
})
+ from crazy_functions.解析项目源代码 import 解析任意code项目
+ function_plugins.update({
+ "解析项目源代码(手动指定和筛选源代码文件类型)": {
+ "Color": "stop",
+ "AsButton": False,
+ "AdvancedArgs": True, # 调用时,唤起高级参数输入区(默认False)
+ "ArgsReminder": "输入时用逗号隔开, *代表通配符, 加了^代表不匹配; 不输入代表全部匹配。例如: \"*.c, ^*.cpp, config.toml, ^*.toml\"", # 高级参数输入区的显示提示
+ "Function": HotReload(解析任意code项目)
+ },
+ })
+ from crazy_functions.询问多个大语言模型 import 同时问询_指定模型
+ function_plugins.update({
+ "询问多个GPT模型(手动指定询问哪些模型)": {
+ "Color": "stop",
+ "AsButton": False,
+ "AdvancedArgs": True, # 调用时,唤起高级参数输入区(默认False)
+ "ArgsReminder": "支持任意数量的llm接口,用&符号分隔。例如chatglm&gpt-3.5-turbo&api2d-gpt-4", # 高级参数输入区的显示提示
+ "Function": HotReload(同时问询_指定模型)
+ },
+ })
###################### 第n组插件 ###########################
return function_plugins
diff --git a/crazy_functions/crazy_functions_test.py b/crazy_functions/crazy_functions_test.py
index 7b0f072..6020fa2 100644
--- a/crazy_functions/crazy_functions_test.py
+++ b/crazy_functions/crazy_functions_test.py
@@ -108,6 +108,13 @@ def test_联网回答问题():
print("当前问答:", cb[-1][-1].replace("\n"," "))
for i, it in enumerate(cb): print亮蓝(it[0]); print亮黄(it[1])
+def test_解析ipynb文件():
+ from crazy_functions.解析JupyterNotebook import 解析ipynb文件
+ txt = "crazy_functions/test_samples"
+ for cookies, cb, hist, msg in 解析ipynb文件(txt, llm_kwargs, plugin_kwargs, chatbot, history, system_prompt, web_port):
+ print(cb)
+
+
# test_解析一个Python项目()
# test_Latex英文润色()
# test_Markdown中译英()
@@ -116,9 +123,8 @@ def test_联网回答问题():
# test_总结word文档()
# test_下载arxiv论文并翻译摘要()
# test_解析一个Cpp项目()
-
-test_联网回答问题()
-
+# test_联网回答问题()
+test_解析ipynb文件()
input("程序完成,回车退出。")
print("退出。")
\ No newline at end of file
diff --git a/crazy_functions/解析JupyterNotebook.py b/crazy_functions/解析JupyterNotebook.py
new file mode 100644
index 0000000..3c9948b
--- /dev/null
+++ b/crazy_functions/解析JupyterNotebook.py
@@ -0,0 +1,140 @@
+from toolbox import update_ui
+from toolbox import CatchException, report_execption, write_results_to_file
+fast_debug = True
+
+
+class PaperFileGroup():
+ def __init__(self):
+ self.file_paths = []
+ self.file_contents = []
+ self.sp_file_contents = []
+ self.sp_file_index = []
+ self.sp_file_tag = []
+
+ # count_token
+ from request_llm.bridge_all import model_info
+ enc = model_info["gpt-3.5-turbo"]['tokenizer']
+ def get_token_num(txt): return len(
+ enc.encode(txt, disallowed_special=()))
+ self.get_token_num = get_token_num
+
+ def run_file_split(self, max_token_limit=1900):
+ """
+ 将长文本分离开来
+ """
+ for index, file_content in enumerate(self.file_contents):
+ if self.get_token_num(file_content) < max_token_limit:
+ self.sp_file_contents.append(file_content)
+ self.sp_file_index.append(index)
+ self.sp_file_tag.append(self.file_paths[index])
+ else:
+ from .crazy_utils import breakdown_txt_to_satisfy_token_limit_for_pdf
+ segments = breakdown_txt_to_satisfy_token_limit_for_pdf(
+ file_content, self.get_token_num, max_token_limit)
+ for j, segment in enumerate(segments):
+ self.sp_file_contents.append(segment)
+ self.sp_file_index.append(index)
+ self.sp_file_tag.append(
+ self.file_paths[index] + f".part-{j}.txt")
+
+
+
+def parseNotebook(filename, enable_markdown=1):
+ import json
+
+ CodeBlocks = []
+ with open(filename, 'r', encoding='utf-8', errors='replace') as f:
+ notebook = json.load(f)
+ for cell in notebook['cells']:
+ if cell['cell_type'] == 'code' and cell['source']:
+ # remove blank lines
+ cell['source'] = [line for line in cell['source'] if line.strip()
+ != '']
+ CodeBlocks.append("".join(cell['source']))
+ elif enable_markdown and cell['cell_type'] == 'markdown' and cell['source']:
+ cell['source'] = [line for line in cell['source'] if line.strip()
+ != '']
+ CodeBlocks.append("Markdown:"+"".join(cell['source']))
+
+ Code = ""
+ for idx, code in enumerate(CodeBlocks):
+ Code += f"This is {idx+1}th code block: \n"
+ Code += code+"\n"
+
+ return Code
+
+
+def ipynb解释(file_manifest, project_folder, llm_kwargs, plugin_kwargs, chatbot, history, system_prompt):
+ from .crazy_utils import request_gpt_model_multi_threads_with_very_awesome_ui_and_high_efficiency
+
+ pfg = PaperFileGroup()
+
+ print(file_manifest)
+ for fp in file_manifest:
+ file_content = parseNotebook(fp, enable_markdown=1)
+ pfg.file_paths.append(fp)
+ pfg.file_contents.append(file_content)
+
+ # <-------- 拆分过长的IPynb文件 ---------->
+ pfg.run_file_split(max_token_limit=1024)
+ n_split = len(pfg.sp_file_contents)
+
+ inputs_array = [r"This is a Jupyter Notebook file, tell me about Each Block in Chinese. Focus Just On Code." +
+ r"If a block starts with `Markdown` which means it's a markdown block in ipynbipynb. " +
+ r"Start a new line for a block and block num use Chinese." +
+ f"\n\n{frag}" for frag in pfg.sp_file_contents]
+ inputs_show_user_array = [f"{f}的分析如下" for f in pfg.sp_file_tag]
+ sys_prompt_array = ["You are a professional programmer."] * n_split
+
+ gpt_response_collection = yield from request_gpt_model_multi_threads_with_very_awesome_ui_and_high_efficiency(
+ inputs_array=inputs_array,
+ inputs_show_user_array=inputs_show_user_array,
+ llm_kwargs=llm_kwargs,
+ chatbot=chatbot,
+ history_array=[[""] for _ in range(n_split)],
+ sys_prompt_array=sys_prompt_array,
+ # max_workers=5, # OpenAI所允许的最大并行过载
+ scroller_max_len=80
+ )
+
+ # <-------- 整理结果,退出 ---------->
+ block_result = " \n".join(gpt_response_collection)
+ chatbot.append(("解析的结果如下", block_result))
+ history.extend(["解析的结果如下", block_result])
+ yield from update_ui(chatbot=chatbot, history=history) # 刷新界面
+
+ # <-------- 写入文件,退出 ---------->
+ res = write_results_to_file(history)
+ chatbot.append(("完成了吗?", res))
+ yield from update_ui(chatbot=chatbot, history=history) # 刷新界面
+
+@CatchException
+def 解析ipynb文件(txt, llm_kwargs, plugin_kwargs, chatbot, history, system_prompt, web_port):
+ chatbot.append([
+ "函数插件功能?",
+ "对IPynb文件进行解析。Contributor: codycjy."])
+ yield from update_ui(chatbot=chatbot, history=history) # 刷新界面
+
+ history = [] # 清空历史
+ import glob
+ import os
+ if os.path.exists(txt):
+ project_folder = txt
+ else:
+ if txt == "":
+ txt = '空空如也的输入栏'
+ report_execption(chatbot, history,
+ a=f"解析项目: {txt}", b=f"找不到本地项目或无权访问: {txt}")
+ yield from update_ui(chatbot=chatbot, history=history) # 刷新界面
+ return
+ if txt.endswith('.ipynb'):
+ file_manifest = [txt]
+ else:
+ file_manifest = [f for f in glob.glob(
+ f'{project_folder}/**/*.ipynb', recursive=True)]
+ if len(file_manifest) == 0:
+ report_execption(chatbot, history,
+ a=f"解析项目: {txt}", b=f"找不到任何.ipynb文件: {txt}")
+ yield from update_ui(chatbot=chatbot, history=history) # 刷新界面
+ return
+ yield from ipynb解释(file_manifest, project_folder, llm_kwargs, plugin_kwargs, chatbot, history, system_prompt, )
diff --git a/crazy_functions/解析项目源代码.py b/crazy_functions/解析项目源代码.py
index 375b87a..bfa473a 100644
--- a/crazy_functions/解析项目源代码.py
+++ b/crazy_functions/解析项目源代码.py
@@ -11,7 +11,7 @@ def 解析源代码新(file_manifest, project_folder, llm_kwargs, plugin_kwargs,
history_array = []
sys_prompt_array = []
report_part_1 = []
-
+
assert len(file_manifest) <= 512, "源文件太多(超过512个), 请缩减输入文件的数量。或者,您也可以选择删除此行警告,并修改代码拆分file_manifest列表,从而实现分批次处理。"
############################## <第一步,逐个文件分析,多线程> ##################################
for index, fp in enumerate(file_manifest):
@@ -63,10 +63,10 @@ def 解析源代码新(file_manifest, project_folder, llm_kwargs, plugin_kwargs,
current_iteration_focus = ', '.join([os.path.relpath(fp, project_folder) for index, fp in enumerate(this_iteration_file_manifest)])
i_say = f'根据以上分析,对程序的整体功能和构架重新做出概括。然后用一张markdown表格整理每个文件的功能(包括{previous_iteration_files_string})。'
inputs_show_user = f'根据以上分析,对程序的整体功能和构架重新做出概括,由于输入长度限制,可能需要分组处理,本组文件为 {current_iteration_focus} + 已经汇总的文件组。'
- this_iteration_history = copy.deepcopy(this_iteration_gpt_response_collection)
+ this_iteration_history = copy.deepcopy(this_iteration_gpt_response_collection)
this_iteration_history.append(last_iteration_result)
result = yield from request_gpt_model_in_new_thread_with_ui_alive(
- inputs=i_say, inputs_show_user=inputs_show_user, llm_kwargs=llm_kwargs, chatbot=chatbot,
+ inputs=i_say, inputs_show_user=inputs_show_user, llm_kwargs=llm_kwargs, chatbot=chatbot,
history=this_iteration_history, # 迭代之前的分析
sys_prompt="你是一个程序架构分析师,正在分析一个项目的源代码。")
report_part_2.extend([i_say, result])
@@ -222,8 +222,8 @@ def 解析一个Golang项目(txt, llm_kwargs, plugin_kwargs, chatbot, history, s
yield from update_ui(chatbot=chatbot, history=history) # 刷新界面
return
yield from 解析源代码新(file_manifest, project_folder, llm_kwargs, plugin_kwargs, chatbot, history, system_prompt)
-
-
+
+
@CatchException
def 解析一个Lua项目(txt, llm_kwargs, plugin_kwargs, chatbot, history, system_prompt, web_port):
history = [] # 清空历史,以免输入溢出
@@ -243,9 +243,9 @@ def 解析一个Lua项目(txt, llm_kwargs, plugin_kwargs, chatbot, history, syst
report_execption(chatbot, history, a = f"解析项目: {txt}", b = f"找不到任何lua文件: {txt}")
yield from update_ui(chatbot=chatbot, history=history) # 刷新界面
return
- yield from 解析源代码新(file_manifest, project_folder, llm_kwargs, plugin_kwargs, chatbot, history, system_prompt)
-
-
+ yield from 解析源代码新(file_manifest, project_folder, llm_kwargs, plugin_kwargs, chatbot, history, system_prompt)
+
+
@CatchException
def 解析一个CSharp项目(txt, llm_kwargs, plugin_kwargs, chatbot, history, system_prompt, web_port):
history = [] # 清空历史,以免输入溢出
@@ -263,4 +263,45 @@ def 解析一个CSharp项目(txt, llm_kwargs, plugin_kwargs, chatbot, history, s
report_execption(chatbot, history, a = f"解析项目: {txt}", b = f"找不到任何CSharp文件: {txt}")
yield from update_ui(chatbot=chatbot, history=history) # 刷新界面
return
- yield from 解析源代码新(file_manifest, project_folder, llm_kwargs, plugin_kwargs, chatbot, history, system_prompt)
+ yield from 解析源代码新(file_manifest, project_folder, llm_kwargs, plugin_kwargs, chatbot, history, system_prompt)
+
+
+@CatchException
+def 解析任意code项目(txt, llm_kwargs, plugin_kwargs, chatbot, history, system_prompt, web_port):
+ txt_pattern = plugin_kwargs.get("advanced_arg")
+ txt_pattern = txt_pattern.replace(",", ",")
+ # 将要匹配的模式(例如: *.c, *.cpp, *.py, config.toml)
+ pattern_include = [_.lstrip(" ,").rstrip(" ,") for _ in txt_pattern.split(",") if _ != "" and not _.strip().startswith("^")]
+ if not pattern_include: pattern_include = ["*"] # 不输入即全部匹配
+ # 将要忽略匹配的文件后缀(例如: ^*.c, ^*.cpp, ^*.py)
+ pattern_except_suffix = [_.lstrip(" ^*.,").rstrip(" ,") for _ in txt_pattern.split(" ") if _ != "" and _.strip().startswith("^*.")]
+ pattern_except_suffix += ['zip', 'rar', '7z', 'tar', 'gz'] # 避免解析压缩文件
+ # 将要忽略匹配的文件名(例如: ^README.md)
+ pattern_except_name = [_.lstrip(" ^*,").rstrip(" ,").replace(".", "\.") for _ in txt_pattern.split(" ") if _ != "" and _.strip().startswith("^") and not _.strip().startswith("^*.")]
+ # 生成正则表达式
+ pattern_except = '/[^/]+\.(' + "|".join(pattern_except_suffix) + ')$'
+ pattern_except += '|/(' + "|".join(pattern_except_name) + ')$' if pattern_except_name != [] else ''
+
+ history.clear()
+ import glob, os, re
+ if os.path.exists(txt):
+ project_folder = txt
+ else:
+ if txt == "": txt = '空空如也的输入栏'
+ report_execption(chatbot, history, a = f"解析项目: {txt}", b = f"找不到本地项目或无权访问: {txt}")
+ yield from update_ui(chatbot=chatbot, history=history) # 刷新界面
+ return
+ # 若上传压缩文件, 先寻找到解压的文件夹路径, 从而避免解析压缩文件
+ maybe_dir = [f for f in glob.glob(f'{project_folder}/*') if os.path.isdir(f)]
+ if len(maybe_dir)>0 and maybe_dir[0].endswith('.extract'):
+ extract_folder_path = maybe_dir[0]
+ else:
+ extract_folder_path = project_folder
+ # 按输入的匹配模式寻找上传的非压缩文件和已解压的文件
+ file_manifest = [f for pattern in pattern_include for f in glob.glob(f'{extract_folder_path}/**/{pattern}', recursive=True) if "" != extract_folder_path and \
+ os.path.isfile(f) and (not re.search(pattern_except, f) or pattern.endswith('.' + re.search(pattern_except, f).group().split('.')[-1]))]
+ if len(file_manifest) == 0:
+ report_execption(chatbot, history, a = f"解析项目: {txt}", b = f"找不到任何文件: {txt}")
+ yield from update_ui(chatbot=chatbot, history=history) # 刷新界面
+ return
+ yield from 解析源代码新(file_manifest, project_folder, llm_kwargs, plugin_kwargs, chatbot, history, system_prompt)
\ No newline at end of file
diff --git a/crazy_functions/询问多个大语言模型.py b/crazy_functions/询问多个大语言模型.py
index fb78145..2939d04 100644
--- a/crazy_functions/询问多个大语言模型.py
+++ b/crazy_functions/询问多个大语言模型.py
@@ -25,6 +25,35 @@ def 同时问询(txt, llm_kwargs, plugin_kwargs, chatbot, history, system_prompt
retry_times_at_unknown_error=0
)
+ history.append(txt)
+ history.append(gpt_say)
+ yield from update_ui(chatbot=chatbot, history=history) # 刷新界面 # 界面更新
+
+
+@CatchException
+def 同时问询_指定模型(txt, llm_kwargs, plugin_kwargs, chatbot, history, system_prompt, web_port):
+ """
+ txt 输入栏用户输入的文本,例如需要翻译的一段话,再例如一个包含了待处理文件的路径
+ llm_kwargs gpt模型参数,如温度和top_p等,一般原样传递下去就行
+ plugin_kwargs 插件模型的参数,如温度和top_p等,一般原样传递下去就行
+ chatbot 聊天显示框的句柄,用于显示给用户
+ history 聊天历史,前情提要
+ system_prompt 给gpt的静默提醒
+ web_port 当前软件运行的端口号
+ """
+ history = [] # 清空历史,以免输入溢出
+ chatbot.append((txt, "正在同时咨询ChatGPT和ChatGLM……"))
+ yield from update_ui(chatbot=chatbot, history=history) # 刷新界面 # 由于请求gpt需要一段时间,我们先及时地做一次界面更新
+
+ # llm_kwargs['llm_model'] = 'chatglm&gpt-3.5-turbo&api2d-gpt-3.5-turbo' # 支持任意数量的llm接口,用&符号分隔
+ llm_kwargs['llm_model'] = plugin_kwargs.get("advanced_arg", 'chatglm&gpt-3.5-turbo') # 'chatglm&gpt-3.5-turbo' # 支持任意数量的llm接口,用&符号分隔
+ gpt_say = yield from request_gpt_model_in_new_thread_with_ui_alive(
+ inputs=txt, inputs_show_user=txt,
+ llm_kwargs=llm_kwargs, chatbot=chatbot, history=history,
+ sys_prompt=system_prompt,
+ retry_times_at_unknown_error=0
+ )
+
history.append(txt)
history.append(gpt_say)
yield from update_ui(chatbot=chatbot, history=history) # 刷新界面 # 界面更新
\ No newline at end of file
diff --git a/docs/WithFastapi.md b/docs/WithFastapi.md
new file mode 100644
index 0000000..188b527
--- /dev/null
+++ b/docs/WithFastapi.md
@@ -0,0 +1,43 @@
+# Running with fastapi
+
+We currently support fastapi in order to solve sub-path deploy issue.
+
+1. change CUSTOM_PATH setting in `config.py`
+
+``` sh
+nano config.py
+```
+
+2. Edit main.py
+
+```diff
+ auto_opentab_delay()
+ - demo.queue(concurrency_count=CONCURRENT_COUNT).launch(server_name="0.0.0.0", server_port=PORT, auth=AUTHENTICATION, favicon_path="docs/logo.png")
+ + demo.queue(concurrency_count=CONCURRENT_COUNT)
+
+ - # 如果需要在二级路径下运行
+ - # CUSTOM_PATH, = get_conf('CUSTOM_PATH')
+ - # if CUSTOM_PATH != "/":
+ - # from toolbox import run_gradio_in_subpath
+ - # run_gradio_in_subpath(demo, auth=AUTHENTICATION, port=PORT, custom_path=CUSTOM_PATH)
+ - # else:
+ - # demo.launch(server_name="0.0.0.0", server_port=PORT, auth=AUTHENTICATION, favicon_path="docs/logo.png")
+
+ + 如果需要在二级路径下运行
+ + CUSTOM_PATH, = get_conf('CUSTOM_PATH')
+ + if CUSTOM_PATH != "/":
+ + from toolbox import run_gradio_in_subpath
+ + run_gradio_in_subpath(demo, auth=AUTHENTICATION, port=PORT, custom_path=CUSTOM_PATH)
+ + else:
+ + demo.launch(server_name="0.0.0.0", server_port=PORT, auth=AUTHENTICATION, favicon_path="docs/logo.png")
+
+if __name__ == "__main__":
+ main()
+```
+
+
+3. Go!
+
+``` sh
+python main.py
+```
diff --git a/main.py b/main.py
index 833720b..55bd680 100644
--- a/main.py
+++ b/main.py
@@ -45,7 +45,7 @@ def main():
gr_L1 = lambda: gr.Row().style()
gr_L2 = lambda scale: gr.Column(scale=scale)
- if LAYOUT == "TOP-DOWN":
+ if LAYOUT == "TOP-DOWN":
gr_L1 = lambda: DummyWith()
gr_L2 = lambda scale: gr.Row()
CHATBOT_HEIGHT /= 2
@@ -88,9 +88,12 @@ def main():
with gr.Row():
with gr.Accordion("更多函数插件", open=True):
dropdown_fn_list = [k for k in crazy_fns.keys() if not crazy_fns[k].get("AsButton", True)]
- with gr.Column(scale=1):
+ with gr.Row():
dropdown = gr.Dropdown(dropdown_fn_list, value=r"打开插件列表", label="").style(container=False)
- with gr.Column(scale=1):
+ with gr.Row():
+ plugin_advanced_arg = gr.Textbox(show_label=True, label="高级参数输入区", visible=False,
+ placeholder="这里是特殊函数插件的高级参数输入区").style(container=False)
+ with gr.Row():
switchy_bt = gr.Button(r"请先从插件列表中选择", variant="secondary")
with gr.Row():
with gr.Accordion("点击展开“文件上传区”。上传本地文件可供红色函数插件调用。", open=False) as area_file_up:
@@ -100,7 +103,7 @@ def main():
top_p = gr.Slider(minimum=-0, maximum=1.0, value=1.0, step=0.01,interactive=True, label="Top-p (nucleus sampling)",)
temperature = gr.Slider(minimum=-0, maximum=2.0, value=1.0, step=0.01, interactive=True, label="Temperature",)
max_length_sl = gr.Slider(minimum=256, maximum=4096, value=512, step=1, interactive=True, label="Local LLM MaxLength",)
- checkboxes = gr.CheckboxGroup(["基础功能区", "函数插件区", "底部输入区", "输入清除键"], value=["基础功能区", "函数插件区"], label="显示/隐藏功能区")
+ checkboxes = gr.CheckboxGroup(["基础功能区", "函数插件区", "底部输入区", "输入清除键", "插件参数区"], value=["基础功能区", "函数插件区"], label="显示/隐藏功能区")
md_dropdown = gr.Dropdown(AVAIL_LLM_MODELS, value=LLM_MODEL, label="更换LLM模型/请求源").style(container=False)
gr.Markdown(description)
@@ -122,11 +125,12 @@ def main():
ret.update({area_input_secondary: gr.update(visible=("底部输入区" in a))})
ret.update({clearBtn: gr.update(visible=("输入清除键" in a))})
ret.update({clearBtn2: gr.update(visible=("输入清除键" in a))})
+ ret.update({plugin_advanced_arg: gr.update(visible=("插件参数区" in a))})
if "底部输入区" in a: ret.update({txt: gr.update(value="")})
return ret
- checkboxes.select(fn_area_visibility, [checkboxes], [area_basic_fn, area_crazy_fn, area_input_primary, area_input_secondary, txt, txt2, clearBtn, clearBtn2] )
+ checkboxes.select(fn_area_visibility, [checkboxes], [area_basic_fn, area_crazy_fn, area_input_primary, area_input_secondary, txt, txt2, clearBtn, clearBtn2, plugin_advanced_arg] )
# 整理反复出现的控件句柄组合
- input_combo = [cookies, max_length_sl, md_dropdown, txt, txt2, top_p, temperature, chatbot, history, system_prompt]
+ input_combo = [cookies, max_length_sl, md_dropdown, txt, txt2, top_p, temperature, chatbot, history, system_prompt, plugin_advanced_arg]
output_combo = [cookies, chatbot, history, status]
predict_args = dict(fn=ArgsGeneralWrapper(predict), inputs=input_combo, outputs=output_combo)
# 提交按钮、重置按钮
@@ -153,14 +157,19 @@ def main():
# 函数插件-下拉菜单与随变按钮的互动
def on_dropdown_changed(k):
variant = crazy_fns[k]["Color"] if "Color" in crazy_fns[k] else "secondary"
- return {switchy_bt: gr.update(value=k, variant=variant)}
- dropdown.select(on_dropdown_changed, [dropdown], [switchy_bt] )
+ ret = {switchy_bt: gr.update(value=k, variant=variant)}
+ if crazy_fns[k].get("AdvancedArgs", False): # 是否唤起高级插件参数区
+ ret.update({plugin_advanced_arg: gr.update(visible=True, label=f"插件[{k}]的高级参数说明:" + crazy_fns[k].get("ArgsReminder", [f"没有提供高级参数功能说明"]))})
+ else:
+ ret.update({plugin_advanced_arg: gr.update(visible=False, label=f"插件[{k}]不需要高级参数。")})
+ return ret
+ dropdown.select(on_dropdown_changed, [dropdown], [switchy_bt, plugin_advanced_arg] )
def on_md_dropdown_changed(k):
return {chatbot: gr.update(label="当前模型:"+k)}
md_dropdown.select(on_md_dropdown_changed, [md_dropdown], [chatbot] )
# 随变按钮的回调函数注册
def route(k, *args, **kwargs):
- if k in [r"打开插件列表", r"请先从插件列表中选择"]: return
+ if k in [r"打开插件列表", r"请先从插件列表中选择"]: return
yield from ArgsGeneralWrapper(crazy_fns[k]["Function"])(*args, **kwargs)
click_handle = switchy_bt.click(route,[switchy_bt, *input_combo, gr.State(PORT)], output_combo)
click_handle.then(on_report_generated, [file_upload, chatbot], [file_upload, chatbot])
@@ -178,7 +187,7 @@ def main():
print(f"如果浏览器没有自动打开,请复制并转到以下URL:")
print(f"\t(亮色主题): http://localhost:{PORT}")
print(f"\t(暗色主题): http://localhost:{PORT}/?__dark-theme=true")
- def open():
+ def open():
time.sleep(2) # 打开浏览器
webbrowser.open_new_tab(f"http://localhost:{PORT}/?__dark-theme=true")
threading.Thread(target=open, name="open-browser", daemon=True).start()
@@ -188,5 +197,13 @@ def main():
auto_opentab_delay()
demo.queue(concurrency_count=CONCURRENT_COUNT).launch(server_name="0.0.0.0", server_port=PORT, auth=AUTHENTICATION, favicon_path="docs/logo.png")
+ # 如果需要在二级路径下运行
+ # CUSTOM_PATH, = get_conf('CUSTOM_PATH')
+ # if CUSTOM_PATH != "/":
+ # from toolbox import run_gradio_in_subpath
+ # run_gradio_in_subpath(demo, auth=AUTHENTICATION, port=PORT, custom_path=CUSTOM_PATH)
+ # else:
+ # demo.launch(server_name="0.0.0.0", server_port=PORT, auth=AUTHENTICATION, favicon_path="docs/logo.png")
+
if __name__ == "__main__":
main()
diff --git a/request_llm/README.md b/request_llm/README.md
index 973adea..4a912d1 100644
--- a/request_llm/README.md
+++ b/request_llm/README.md
@@ -1,4 +1,4 @@
-# 如何使用其他大语言模型(v3.0分支测试中)
+# 如何使用其他大语言模型
## ChatGLM
@@ -15,7 +15,7 @@ LLM_MODEL = "chatglm"
---
-## Text-Generation-UI (TGUI)
+## Text-Generation-UI (TGUI,调试中,暂不可用)
### 1. 部署TGUI
``` sh
diff --git a/request_llm/bridge_all.py b/request_llm/bridge_all.py
index c5219d4..2dd790c 100644
--- a/request_llm/bridge_all.py
+++ b/request_llm/bridge_all.py
@@ -1,16 +1,17 @@
"""
- 该文件中主要包含2个函数
+ 该文件中主要包含2个函数,是所有LLM的通用接口,它们会继续向下调用更底层的LLM模型,处理多模型并行等细节
- 不具备多线程能力的函数:
- 1. predict: 正常对话时使用,具备完备的交互功能,不可多线程
+ 不具备多线程能力的函数:正常对话时使用,具备完备的交互功能,不可多线程
+ 1. predict(...)
- 具备多线程调用能力的函数
- 2. predict_no_ui_long_connection:在实验过程中发现调用predict_no_ui处理长文档时,和openai的连接容易断掉,这个函数用stream的方式解决这个问题,同样支持多线程
+ 具备多线程调用能力的函数:在函数插件中被调用,灵活而简洁
+ 2. predict_no_ui_long_connection(...)
"""
import tiktoken
-from functools import wraps, lru_cache
+from functools import lru_cache
from concurrent.futures import ThreadPoolExecutor
+from toolbox import get_conf
from request_llm.bridge_chatgpt import predict_no_ui_long_connection as chatgpt_noui
from request_llm.bridge_chatgpt import predict as chatgpt_ui
@@ -42,18 +43,37 @@ class LazyloadTiktoken(object):
def decode(self, *args, **kwargs):
encoder = self.get_encoder(self.model)
return encoder.decode(*args, **kwargs)
-
+
+# Endpoint 重定向
+API_URL_REDIRECT, = get_conf("API_URL_REDIRECT")
+openai_endpoint = "https://api.openai.com/v1/chat/completions"
+api2d_endpoint = "https://openai.api2d.net/v1/chat/completions"
+# 兼容旧版的配置
+try:
+ API_URL, = get_conf("API_URL")
+ if API_URL != "https://api.openai.com/v1/chat/completions":
+ openai_endpoint = API_URL
+ print("警告!API_URL配置选项将被弃用,请更换为API_URL_REDIRECT配置")
+except:
+ pass
+# 新版配置
+if openai_endpoint in API_URL_REDIRECT: openai_endpoint = API_URL_REDIRECT[openai_endpoint]
+if api2d_endpoint in API_URL_REDIRECT: api2d_endpoint = API_URL_REDIRECT[api2d_endpoint]
+
+
+# 获取tokenizer
tokenizer_gpt35 = LazyloadTiktoken("gpt-3.5-turbo")
tokenizer_gpt4 = LazyloadTiktoken("gpt-4")
get_token_num_gpt35 = lambda txt: len(tokenizer_gpt35.encode(txt, disallowed_special=()))
get_token_num_gpt4 = lambda txt: len(tokenizer_gpt4.encode(txt, disallowed_special=()))
+
model_info = {
# openai
"gpt-3.5-turbo": {
"fn_with_ui": chatgpt_ui,
"fn_without_ui": chatgpt_noui,
- "endpoint": "https://api.openai.com/v1/chat/completions",
+ "endpoint": openai_endpoint,
"max_token": 4096,
"tokenizer": tokenizer_gpt35,
"token_cnt": get_token_num_gpt35,
@@ -62,7 +82,7 @@ model_info = {
"gpt-4": {
"fn_with_ui": chatgpt_ui,
"fn_without_ui": chatgpt_noui,
- "endpoint": "https://api.openai.com/v1/chat/completions",
+ "endpoint": openai_endpoint,
"max_token": 8192,
"tokenizer": tokenizer_gpt4,
"token_cnt": get_token_num_gpt4,
@@ -72,7 +92,7 @@ model_info = {
"api2d-gpt-3.5-turbo": {
"fn_with_ui": chatgpt_ui,
"fn_without_ui": chatgpt_noui,
- "endpoint": "https://openai.api2d.net/v1/chat/completions",
+ "endpoint": api2d_endpoint,
"max_token": 4096,
"tokenizer": tokenizer_gpt35,
"token_cnt": get_token_num_gpt35,
@@ -81,7 +101,7 @@ model_info = {
"api2d-gpt-4": {
"fn_with_ui": chatgpt_ui,
"fn_without_ui": chatgpt_noui,
- "endpoint": "https://openai.api2d.net/v1/chat/completions",
+ "endpoint": api2d_endpoint,
"max_token": 8192,
"tokenizer": tokenizer_gpt4,
"token_cnt": get_token_num_gpt4,
@@ -190,7 +210,7 @@ def predict_no_ui_long_connection(inputs, llm_kwargs, history, sys_prompt, obser
return_string_collect.append( f"【{str(models[i])} 说】: {future.result()} " )
window_mutex[-1] = False # stop mutex thread
- res = '
\n\n---\n\n'.join(return_string_collect)
+ res = '
\n\n---\n\n'.join(return_string_collect)
return res
diff --git a/request_llm/bridge_chatglm.py b/request_llm/bridge_chatglm.py
index 7af2835..8eef322 100644
--- a/request_llm/bridge_chatglm.py
+++ b/request_llm/bridge_chatglm.py
@@ -92,8 +92,8 @@ def predict_no_ui_long_connection(inputs, llm_kwargs, history=[], sys_prompt="",
# chatglm 没有 sys_prompt 接口,因此把prompt加入 history
history_feedin = []
+ history_feedin.append(["What can I do?", sys_prompt])
for i in range(len(history)//2):
- history_feedin.append(["What can I do?", sys_prompt] )
history_feedin.append([history[2*i], history[2*i+1]] )
watch_dog_patience = 5 # 看门狗 (watchdog) 的耐心, 设置5秒即可
@@ -131,10 +131,13 @@ def predict(inputs, llm_kwargs, plugin_kwargs, chatbot, history=[], system_promp
inputs = core_functional[additional_fn]["Prefix"] + inputs + core_functional[additional_fn]["Suffix"]
history_feedin = []
+ history_feedin.append(["What can I do?", system_prompt] )
for i in range(len(history)//2):
- history_feedin.append(["What can I do?", system_prompt] )
history_feedin.append([history[2*i], history[2*i+1]] )
for response in glm_handle.stream_chat(query=inputs, history=history_feedin, max_length=llm_kwargs['max_length'], top_p=llm_kwargs['top_p'], temperature=llm_kwargs['temperature']):
chatbot[-1] = (inputs, response)
- yield from update_ui(chatbot=chatbot, history=history)
\ No newline at end of file
+ yield from update_ui(chatbot=chatbot, history=history)
+
+ history.extend([inputs, response])
+ yield from update_ui(chatbot=chatbot, history=history)
\ No newline at end of file
diff --git a/request_llm/bridge_chatgpt.py b/request_llm/bridge_chatgpt.py
index 2d8a8bc..98bb74f 100644
--- a/request_llm/bridge_chatgpt.py
+++ b/request_llm/bridge_chatgpt.py
@@ -21,7 +21,7 @@ import importlib
# config_private.py放自己的秘密如API和代理网址
# 读取时首先看是否存在私密的config_private配置文件(不受git管控),如果有,则覆盖原config文件
-from toolbox import get_conf, update_ui, is_any_api_key, select_api_key
+from toolbox import get_conf, update_ui, is_any_api_key, select_api_key, what_keys
proxies, API_KEY, TIMEOUT_SECONDS, MAX_RETRY = \
get_conf('proxies', 'API_KEY', 'TIMEOUT_SECONDS', 'MAX_RETRY')
@@ -118,7 +118,7 @@ def predict(inputs, llm_kwargs, plugin_kwargs, chatbot, history=[], system_promp
"""
if is_any_api_key(inputs):
chatbot._cookies['api_key'] = inputs
- chatbot.append(("输入已识别为openai的api_key", "api_key已导入"))
+ chatbot.append(("输入已识别为openai的api_key", what_keys(inputs)))
yield from update_ui(chatbot=chatbot, history=history, msg="api_key已导入") # 刷新界面
return
elif not is_any_api_key(chatbot._cookies['api_key']):
@@ -141,7 +141,7 @@ def predict(inputs, llm_kwargs, plugin_kwargs, chatbot, history=[], system_promp
try:
headers, payload = generate_payload(inputs, llm_kwargs, history, system_prompt, stream)
except RuntimeError as e:
- chatbot[-1] = (inputs, f"您提供的api-key不满足要求,不包含任何可用于{llm_kwargs['llm_model']}的api-key。")
+ chatbot[-1] = (inputs, f"您提供的api-key不满足要求,不包含任何可用于{llm_kwargs['llm_model']}的api-key。您可能选择了错误的模型或请求源。")
yield from update_ui(chatbot=chatbot, history=history, msg="api-key不满足要求") # 刷新界面
return
diff --git a/toolbox.py b/toolbox.py
index 7dc72c5..3147ce9 100644
--- a/toolbox.py
+++ b/toolbox.py
@@ -32,23 +32,23 @@ def ArgsGeneralWrapper(f):
装饰器函数,用于重组输入参数,改变输入参数的顺序与结构。
"""
def decorated(cookies, max_length, llm_model, txt, top_p, temperature,
- chatbot, history, system_prompt, models, ipaddr: gr.Request, *args):
+ chatbot, history, system_prompt, plugin_advanced_arg, models, ipaddr: gr.Request, *args):
""""""
# 引入一个有cookie的chatbot
cookies.update({
- 'top_p':top_p,
+ 'top_p':top_p,
'temperature':temperature,
})
llm_kwargs = {
'api_key': cookies['api_key'],
'llm_model': llm_model,
- 'top_p':top_p,
+ 'top_p':top_p,
'max_length': max_length,
'temperature': temperature,
'ipaddr': ipaddr.client.host
}
plugin_kwargs = {
- # 目前还没有
+ "advanced_arg": plugin_advanced_arg,
}
chatbot_with_cookie = ChatBotWithCookies(cookies)
chatbot_with_cookie.write_list(chatbot)
@@ -237,7 +237,7 @@ def markdown_convertion(txt):
return content
else:
return tex2mathml_catch_exception(content)
-
+
def markdown_bug_hunt(content):
"""
解决一个mdx_math的bug(单$包裹begin命令时多余\n', '')
return content
-
+
if ('$' in txt) and ('```' not in txt): # 有$标识的公式符号,且没有代码段```的标识
# convert everything to html format
@@ -266,7 +266,7 @@ def markdown_convertion(txt):
def close_up_code_segment_during_stream(gpt_reply):
"""
在gpt输出代码的中途(输出了前面的```,但还没输出完后面的```),补上后面的```
-
+
Args:
gpt_reply (str): GPT模型返回的回复字符串。
@@ -473,6 +473,19 @@ def is_any_api_key(key):
else:
return is_openai_api_key(key) or is_api2d_key(key)
+def what_keys(keys):
+ avail_key_list = {'OpenAI Key':0, "API2D Key":0}
+ key_list = keys.split(',')
+
+ for k in key_list:
+ if is_openai_api_key(k):
+ avail_key_list['OpenAI Key'] += 1
+
+ for k in key_list:
+ if is_api2d_key(k):
+ avail_key_list['API2D Key'] += 1
+
+ return f"检测到: OpenAI Key {avail_key_list['OpenAI Key']} 个,API2D Key {avail_key_list['API2D Key']} 个"
def select_api_key(keys, llm_model):
import random
@@ -488,7 +501,7 @@ def select_api_key(keys, llm_model):
if is_api2d_key(k): avail_key_list.append(k)
if len(avail_key_list) == 0:
- raise RuntimeError(f"您提供的api-key不满足要求,不包含任何可用于{llm_model}的api-key。")
+ raise RuntimeError(f"您提供的api-key不满足要求,不包含任何可用于{llm_model}的api-key。您可能选择了错误的模型或请求源。")
api_key = random.choice(avail_key_list) # 随机负载均衡
return api_key
@@ -539,7 +552,7 @@ class DummyWith():
它的作用是……额……没用,即在代码结构不变得情况下取代其他的上下文管理器。
上下文管理器是一种Python对象,用于与with语句一起使用,
以确保一些资源在代码块执行期间得到正确的初始化和清理。
- 上下文管理器必须实现两个方法,分别为 __enter__()和 __exit__()。
+ 上下文管理器必须实现两个方法,分别为 __enter__()和 __exit__()。
在上下文执行开始的情况下,__enter__()方法会在代码块被执行前被调用,
而在上下文执行结束时,__exit__()方法则会被调用。
"""
@@ -550,7 +563,33 @@ class DummyWith():
return
-if __name__ == '__main__':
- private_upload = './private_upload'
- for r, d, f in os.walk(private_upload):
- print(r, f)
+def run_gradio_in_subpath(demo, auth, port, custom_path):
+ def is_path_legal(path: str)->bool:
+ '''
+ check path for sub url
+ path: path to check
+ return value: do sub url wrap
+ '''
+ if path == "/": return True
+ if len(path) == 0:
+ print("ilegal custom path: {}\npath must not be empty\ndeploy on root url".format(path))
+ return False
+ if path[0] == '/':
+ if path[1] != '/':
+ print("deploy on sub-path {}".format(path))
+ return True
+ return False
+ print("ilegal custom path: {}\npath should begin with \'/\'\ndeploy on root url".format(path))
+ return False
+
+ if not is_path_legal(custom_path): raise RuntimeError('Ilegal custom path')
+ import uvicorn
+ import gradio as gr
+ from fastapi import FastAPI
+ app = FastAPI()
+ if custom_path != "/":
+ @app.get("/")
+ def read_main():
+ return {"message": f"Gradio is running at: {custom_path}"}
+ app = gr.mount_gradio_app(app, demo, path=custom_path)
+ uvicorn.run(app, host="0.0.0.0", port=port) # , auth=auth
\ No newline at end of file
diff --git a/version b/version
index bb462e2..ec50d82 100644
--- a/version
+++ b/version
@@ -1,5 +1,5 @@
{
- "version": 3.1,
+ "version": 3.2,
"show_feature": true,
- "new_feature": "添加支持清华ChatGLM和GPT-4 <-> 改进架构,支持与多个LLM模型同时对话 <-> 添加支持API2D(国内,可支持gpt4)<-> 支持多API-KEY负载均衡(并列填写,逗号分割) <-> 添加输入区文本清除按键"
+ "new_feature": "现函数插件可读取高级参数(解读任意语言代码+同时询问任意的LLM组合)<-> 添加联网(Google)回答问题插件 <-> 修复ChatGLM上下文BUG <-> 添加支持清华ChatGLM和GPT-4 <-> 改进架构,支持与多个LLM模型同时对话 <-> 添加支持API2D(国内,可支持gpt4)"
}